第6章 学習

図6.1 | アカウミガメの子ガメは、海の見つけ方と泳ぎ方を知って生まれてきます。ウミガメと違い、人間は泳ぎ方(とサーフィンの仕方)を学ばなければなりません。(credit “turtle”: modification of work by Becky Skiba, USFWS; credit “surfer”: modification of work by Mike Baird)
この章の概要
6.1 学習とは何でしょうか?
6.2 古典的条件付け
6.3 オペラント条件付け
6.4 観察学習(モデリング)
はじめに
誰もいない長く伸びた浜辺に夏の太陽の光が燦々と降り注いでいます。突然、小さな灰色の頭がひとつ砂から飛び出し、そして次から次へと現れてきます。やがて、浜辺はアカウミガメの子ガメでいっぱいになります(図6.1)。生後数分しか経っていないのに、子ガメたちは何をすべきかをよく知っています。彼らのヒレは熱い砂の上を移動するにはあまり効率的ではありませんが、それでも彼らは本能的に前進します。頭上を旋回するカモメにすぐに食べられてしまうものや、お腹をすかせて穴から飛び出してきたミナミスナガニの食事になってしまうものもあります。このような危険にもかかわらず、子ガメたちは安全な巣を離れて海を目指すように駆り立てられます。
同じビーチのそう遠くないところで、ベンと息子のジュリアンはサーフボードに乗って海に漕ぎ出しています。波が近づいてきました。ジュリアンはボードの上で膝を立て、立ち上がって数秒間波に乗った後、バランスを崩します。ジュリアンはすぐに海から浮かび上がり、父親が波の表面に乗るのを見届けます。
親の助けを借りずとも海を見つけて泳ぎだすやり方を知っているウミガメの赤ちゃんとは違い、私たちは生まれながらにして泳ぎ方(あるいはサーフィンの仕方)を知っているわけではありません。それでも、私たち人間は学ぶ能力に長けていると自負しています。実際、何千年もの間、文化の違いを超えて、私たちは学ぶことだけを目的とした機関を作ってきました。しかし、人が学ぶとはいったいどのようなことなのか、あなたは考えたことはありますか?私たちが知っているものを知るようになるためには、どのようなプロセスが働いているのでしょうか?この章では、学習が行われる主な方法に焦点を当てます。
6.1 学習とは何でしょうか?
学習目標
この節が終わるまでに、あなたは次のことができるようになります:
- 学習した行動が本能や反射とどのように違うかを説明する
- 学習を定義する
- 古典的条件付け、オペラント条件付け、および観察学習という3つの基本的な学習形態を認識し、定義する
鳥は巣を作り、冬になると渡りをします。乳児は母親の乳房に吸い付きます。犬は濡れた毛皮から水を振り払います。サケは産卵のために川を遡り、クモは複雑な巣を張ります。一見、無関係に見えるこれらの行動には、どのような共通点があるのでしょうか?これらはすべて学習されていない行動です。本能も反射も、生物が生まれながらにして持っている生得的(学習されていない)行動です。反射とは、環境中の特定の刺激に対する運動や神経の反応のことです。反射は、本能よりも単純である傾向があり、特定の体の部位や系の活動を伴い(例:膝蓋反射や明るい場所での瞳孔の収縮)、中枢神経系のより原始的な中枢(例:脊髄や延髄)が関与しています。一方、本能は、成熟や季節の変わり目など、より幅広い事象によって引き起こされる生得的行動です。本能は、より複雑な行動パターンであり、生物全体の動き(例:性行為や渡りなど)を伴い、より高次の脳中枢が関与しています。
反射も本能も、生物が環境に適応するために役立つものであり、学習しなければならないわけではありません。たとえば、健康な人間の赤ん坊には皆、生まれたときから吸啜反射が備わっています。赤ん坊は、人工の乳首(哺乳瓶)であれ、人間の乳首であれ、吸い方を知った状態で生まれてきます。ウミガメの子が海に向かって移動することを誰も教えないのと同じように、赤ん坊に吸い方を教える人はいません。学習は、反射や本能と同様に、生物が環境に適応することを可能にします。しかし、本能や反射とは異なり、学習された行動には変化と経験が伴います:学習とは、経験から生じる行動や知識の比較的永続的な変化のことです。先に述べた生得的行動とは対照的に、学習は経験を通じて知識と技能を習得することです。サーフィンのシナリオを振り返ってみると、ジュリアンが父親のように波に乗れるようになることを学習するまでには、もっと長い時間をかけてサーフボードを使ったトレーニングをしなければなりません。
サーフィンの学習に限らず、複雑な学習過程(たとえば、心理学の学問分野について学習すること)では、意識的な過程と無意識的な過程が複雑に絡み合っています。従来、学習は、その最も単純な構成要素、つまり、私たちの心が出来事の間で自動的に作り出す連想という観点から研究されてきました。私たちの心には、密接に関連した出来事や連続した出来事を結びつけるという自然な傾向があります。連合学習は、生物が環境の中で一緒に起こる刺激や出来事を結びつけるときに起こります。あなたは、この章で取り上げる3つの基本的な学習過程では、いずれも連合学習が中心となっていることがわかるでしょう:古典的条件付けは、無意識的な過程を伴う傾向があります。オペラント条件付けは、意識的な過程を伴う傾向があります。観察学習は、意識的、無意識的にかかわらず、すべての基本的な連想過程に社会的および認知的な層を加えます。これらの学習過程については、この章の後半で詳しく議論しますが、あなたが心理学的な観点から学習をどのように理解するかを探求し始めるにあたって、それぞれの過程の概要を知っておくと便利です。
古典的条件付け(パブロフの条件付けとしても知られています)では、生物は繰り返し一緒になって起こる出来事(または刺激)を関連付けることを学びます。私たちは日常生活の中でこの過程を経験しています。たとえば、あなたは嵐の日に空に稲妻が光るのを見て、その後に大きな雷鳴が聞こえました。雷の音を聞くと、あなたは自然と飛び上がってしまいます(大きな音には反射によってその効果があります)。稲妻は、間近に迫った雷鳴を確実に予測するので、あなたはこの2つを関連付けて、稲妻を見ると飛び上がるようになるかもしれません。心理学の研究者は、この連想過程を、行動という目に見えて測定できるものに着目することにより研究しています。研究者たちは、ある刺激が反射を引き起こすなら、訓練することにより別の刺激で同じ反射を引き起こすことができるのではないか、と考えます。オペラント条件付けでは、やはり、生物は行動とその結果(強化または弱化)という出来事を関連付けることを学びます。嬉しい結果は、その行動を将来においてさらに行うことを奨励する一方で、罰は、その行動を抑止することになります。あなたが愛犬のホドーにお座りを教えているところを想像してください。あなたはホドーに「お座り」と言い、お座りしたらおやつを与えます。繰り返して経験するうちに、ホドーはお座りする行動とおやつをもらうことを関連付け始めます。ホドーは、おすわりの結果として、犬用のビスケットがもらえることを学習します(図6.2)。逆に、ある行動をしたときに罰せられると、その行動を避けるように条件付けられます(たとえば、見えない電気柵の境界を越えたときに小さなショックを受けるなど)。

図6.2 | オペラント条件付けでは、反応は結果と関連付けられます。この犬は、ある行動をするとおやつをもらえると学習しました。(credit: Crystal Rolfe)
観察学習は、古典的条件付けとオペラント条件付けの有効範囲を広げます。古典的条件付けやオペラント条件付けでは直接的な経験を通じてのみ学習が起きるのに対し、観察学習とは他者を見て、それらがやっていることを真似る過程です。人間や他の動物の学習の多くは観察学習によるものです。観察学習がもたらす更なる有効範囲についての考え方を得るために、冒頭で紹介したベンと息子のジュリアンを考えてみましょう。ジュリアンは、試行錯誤だけによって学ぶのではなく、観察によってどのようにサーフィンを学ぶことができるでしょうか?父親を見ることで、成功をもたらす動きを真似し、失敗につながる動きを避けることができます。あなたも誰かを見て何かのやり方を学んだことがありますか?
本章で取り上げるアプローチはすべて、心理学の中の行動主義と呼ばれる特定の学派に属しています(行動主義については、私たちは次の節で議論します)。しかしながら、これらのアプローチが、学習についての研究の全体を表しているわけではありません。記憶と認知など、心理学のさまざまな分野で、学習に関する別の学派が形成されてきているため、あなたは他の章を読むことで、このトピックについての理解を深めることができるでしょう。これらの学派は時間の経過とともに収束する傾向にあります。たとえば、本章であなたは、行動主義において認知がどのようにして大きな役割を果たすようになったかを見ることになります(行動主義のもっと極端な支持者は、かつては「行動は環境によって引き起こされ、思考は介在しない」と主張していました)。
6.2 古典的条件付け
学習目標
この節が終わるまでに、あなたは次のことができるようになります:
- 古典的条件付けがどのように起こるかを説明する
- 獲得、消去、自発的回復、般化、分化の過程を要約する
イワン・パブロフという名前に聞き覚えはありませんか?もしあなたが心理学の勉強を始めたばかりであっても、パブロフと彼の有名な犬については聞いたことがあるかもしれません。
パブロフ(1849-1936)は、ロシアの科学者で、犬を使った広範な研究を行い、古典的条件付けの実験でよく知られています(図6.3)。私たちが前節で簡単に議論したように、古典的条件付けとは、私たちが刺激の関連付けを学び、その結果、出来事を予測する過程のことです。

図6.3 | イワン・パブロフによる犬の消化器系の研究は、思いがけず、古典的条件付けとして知られる学習過程の発見につながりました。
学習がどのようにして起こるかについてパブロフがその結論にたどり着いたのは、まったくの偶然でした。パブロフは心理学者ではなく、生理学者でした。生理学者は、分子レベルから、細胞のレベル、器官系、生物全体に至るまで、生物の生命プロセスを研究します。パブロフが興味を持っていた領域は、消化器系でした(Hunt, 2007)。パブロフは、犬を使った研究で、さまざまな食物に反応して分泌される唾液の量を測定しました。やがてパブロフ(Pavlov, 1927)は、犬が食べ物の味だけでなく、食べ物を見たとき、空の皿を見たとき、さらには実験助手の足音でも唾液を分泌するようになったことを観察しました。口の中の食べ物に対する唾液分泌は反射的に行われるので、学習は関連していません。しかしながら、犬は自然のままでは空の皿を見ても足音を聞いても唾液を出しません。
このような異常な反応に興味を持ったパブロフは、彼が犬の「精神的分泌」と名付けたものをどのようにして説明することができるかを考えました(Pavlov, 1927)。パブロフは、この現象を客観的な態様で調べるために、どのような刺激を与えると犬が唾液を分泌するのかを観察する、注意深く制御された一連の実験を計画しました。彼は、ベルの音、光、足に触れるなど、明らかに食べ物とは関係のない刺激に反応して唾液を分泌するように犬を訓練することができました。パブロフは実験を通して、生物には環境に対する2種類の反応があることに気づきました:それは(1)無条件(学習されていない)反応(すなわち、反射)と、(2)条件(学習された)反応です。
パブロフの実験では、犬は肉粉を提示されるたびに唾液を出しました。この状況における肉粉は無条件刺激(UCS)、すなわち生物の反射的な反応を引き起こす刺激です。犬の唾液分泌は無条件反応(UCR)、すなわち所与の刺激に対する自然な(学習されていない)反応です。条件付けの前では、犬の刺激と反応を次のように考えることができます:
\[ \rm 肉粉(UCS) → 唾液分泌(UCR) \]
古典的条件付けでは、無条件刺激の直前に中性刺激を提示します。パブロフは、音(ベルの音のようなもの)を鳴らしてから、犬に肉粉を与えました(図6.4)。この音は中性刺激(NS)であり、それは自然には反応を引き起こさないような刺激のことです。条件付けの前には、犬は音を聞いただけでは唾液を出しませんでした。なぜなら、音が犬にとって何の関連性もないからです。
\[ \rm 音(NS) + 肉粉(UCS) → 唾液分泌(UCR) \]
パブロフが音と肉粉をペアにして何度も繰り返すと、それまで中性刺激であったもの(音)でも、犬の唾液分泌を引き起こすようになりました。したがって、中性刺激が条件刺激(CS)となりました。条件刺激とは、繰り返し無条件刺激と対にされた後に、反応を引き起こすようになった刺激のことです。やがて犬は、それまで助手の足音で唾液を出していたのと同じように、音だけで唾液を出し始めるようになりました。条件刺激によって引き起こされる行動を条件反応(CR)といいます。パブロフの犬の場合は、音(CS)と餌をもらうことを関連付けて学習し、餌を期待して唾液を出すようになりました(CR)。
\[ \rm 音(CS) → 唾液分泌(CR) \]

図6.4 | 条件付けの前では、無条件刺激(食べ物)は無条件反応(唾液分泌)を生じさせ、中性刺激(ベル)は反応を生じさせません。条件付けの途中では、無条件刺激(食べ物)が中性刺激(ベル)の提示の直後に繰り返し与えられます。条件付けの後では、中性刺激だけで条件反応(唾液分泌)が起こり、中性刺激は条件刺激となります。
学習へのリンク
パブロフと彼の犬についてのビデオ(http://openstax.org/l/pavlov2)を見て、さらに学んでください。
古典的条件付けの現実世界への応用
古典的条件付けは現実世界でどのように機能するのでしょうか?がんと診断されたモイシャの事例を考えてみましょう。初めて化学療法を受けたとき、彼女は化学物質を注射された直後に嘔吐しました。実際のところ、彼女は化学療法のために医者のもとに行くたびに、薬液を注入された直後に嘔吐しました。モイシャの治療は成功し、彼女のがんは寛解に向かいました。現在、彼女は半年に一度の検診のために腫瘍医の診察室に行くと、吐き気を催すようになりました。この事例では、化学療法の薬物が無条件刺激(UCS)、嘔吐が無条件反応(UCR)、医師の診察室がUCSと対になった後の条件刺激(CS)、吐き気が条件反応(CR)となります。モイシャが摂取する化学療法の薬物は、注射器による注射で投与されると仮定しましょう。医師の診察室に入ったモイシャは、注射器を見て、薬物を投与されます。医師の診察室に加えて、モイシャは注射器と薬物を関連付けることを学び、注射器に対して吐き気を伴う反応をするようになります。これは高次(または二次)条件付けの例で、そこでは、条件付けられた刺激(医師の診察室)が別の刺激(注射器)を条件付ける役割を果たします。二次の条件付けよりも高次のことを達成するのは難しいです。たとえば、モイシャが医師の診察室で化学療法の薬物の注射を受けるたびに誰かがベルを鳴らしたとしても、ベルに反応してモイシャの気分が悪くなることはないでしょう。
もう1つの古典的条件付けの例を考えてみましょう。あなたはタイガーという名前の猫を飼っていて、彼女はとても甘えん坊だとします。あなたは、タイガーの食事を別の棚に置いておき、キャットフードの缶詰を開けるときだけに使う特別な電動缶切りも持っています。食事のたびに、タイガーは電動缶切りの独特の音(「ズズズ」)を聞いてから、食事をします。タイガーは、「ズズズ」という音を聞くと、餌がもらえるということをすぐに覚えます。あなたは、タイガーが電動缶切りの音を聞いたときに何をすると思いますか?おそらく興奮して、あなたが餌を用意しているところに走っていくでしょう。これは古典的条件付けの一例です。この場合、UCS、CS、UCR、CRは何でしょうか?
タイガーの食べ物を入れている棚がキーキーと音を立てるようになったとしたら、どうなるでしょうか?この場合、タイガーは「キーキー」(棚)、「ズズズ」(電動缶切り)という音を聞いてから、食べ物を手に入れます。タイガーは棚の「キーキー」という音を聞くと興奮することを覚えるでしょう。新しい中性刺激(「キーキー」)と条件刺激(「ズズズ」)を対にすることを、高次の条件付け、または二次の条件付けといいます。これはつまり、あなたが、缶切りという条件刺激を使って、音を立てる棚という別の刺激を条件付けていることを意味します(図6.5)。二次の条件付けよりも高次のことを実現するのは難しいです。たとえば、あなたがベルを鳴らして、棚を開けて(「キーキー」)、缶切りを使って(「ズズズ」)、タイガーに餌を与えたとしても、タイガーがベルを聞いただけで興奮することはないでしょう。
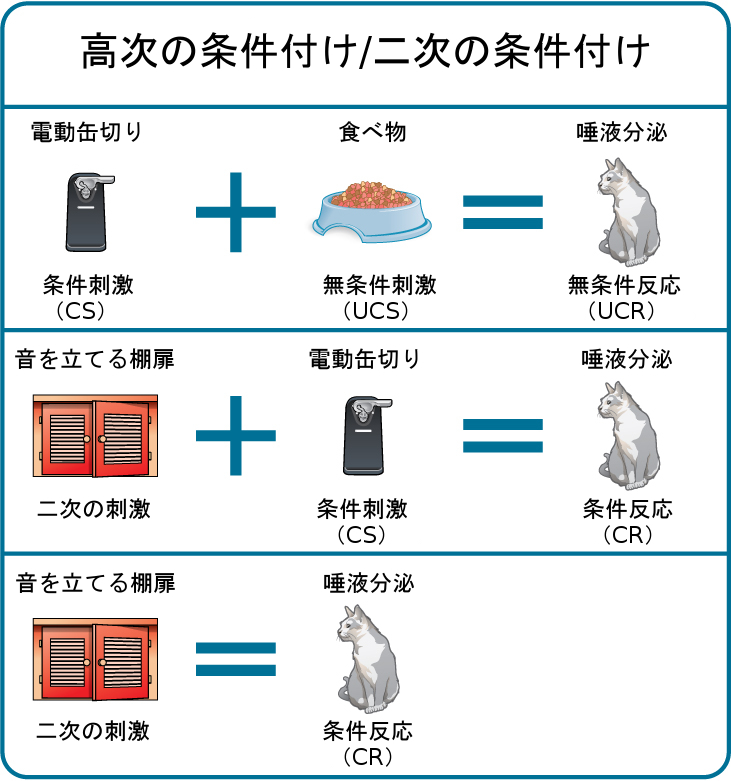
図6.5 | 高次の条件付けでは、確立された条件刺激が新しい中性刺激(二次の刺激)と対になっているので、最終的には、当初の条件刺激が提示されなくても、新しい刺激で条件反応が誘発されるようになります。
日常へのつながり
スティングレイ・シティでの古典的条件付け
ケイトと彼女の配偶者は、最近ケイマン諸島で休暇を過ごし、スティングレイ・シティへのボートツアーを予約しました。そこでは、彼女たちはアカエイに食べ物をやり、一緒に泳ぐことができます。船長は、普段なら単独行動をするアカエイがいかにして人間との交流に慣れたのかを説明してくれました。40年ほど前、漁師たちが堡礁近くのある特定の砂州で魚や巻貝(無条件刺激)を洗い始めるようになると、大量のアカエイが泳いできて、漁師が海に投げ入れたものを食べる(無条件反応)ということがあり、それは何年も続きました。1980年代後半になると、アカエイの大群が存在するという話がスキューバダイバーの間で広まり、ダイバーが手渡しでアカエイに餌を与えるようになりました。そのうちに、この地域のアカエイは、パブロフの犬とほとんど同じように古典的条件付けされました。それらがボートのエンジン音を聞くと(条件刺激となる中性刺激)、餌がもらえるであろうということがわかります(条件反応)。
彼女たちがスティングレイ・シティに到着するやいなや、20匹を超えるアカエイがツアーボートを取り囲みました。夫妻はアカエイの好物であるイカの袋を持って海に入りました。アカエイの大群は、まるでお腹をすかせた猫のように、2人の足にぶつかったり擦り寄ったりしてきました(図6.6)。ケイトは、この素晴らしい生き物に餌を与えたり、撫でたり、運が良ければキスをしたりすることができました。その後、イカがすべてなくなると、アカエイもいなくなってしまいました。

図6.6 | ケイマン諸島のスティングレイ・シティでアカエイを抱くケイト。これらのアカエイは、ボートのモーター音と観光客が提供する餌を関連付けるように古典的条件付けされています。(credit: Kathryn Dumper)
古典的条件付けは、人間にも、そして赤ん坊にすら当てはまります。たとえば、サラは生後6か月の娘アンジェリーナのために、青い容器に入った粉ミルクを買っています。サラが粉ミルクの容器を取り出すたびに、アンジェリーナは興奮して食べ物の方に手を伸ばそうとし、ほとんどの場合、唾液を出します。なぜアンジェリーナは粉ミルクの容器を見て興奮するのでしょうか?ここでのUCS、CS、UCR、およびCRは何でしょうか?
ここまでは、すべての例で食べ物が関係していましたが、古典的条件付けは、食べ物を与えられるという基本的な欲求を超えて広がるものです。先ほどの、目に見えない犬用電気フェンスを飼い主が設置した犬の例を考えてみましょう。小さな電気ショック(無条件刺激)を与えると、不快感(無条件反応)が生じます。無条件刺激(ショック)が中性刺激(庭の端)と対になっている場合、犬は不快感(無条件反応)と庭の端(条件刺激)を関連付け、設定された境界内にとどまるようになります。この例では、庭の端が犬の恐怖と不安を引き起こしています。恐怖と不安は条件反応です。
学習へのリンク
条件付けをユーモラスに表現したテレビ番組『The Office(ジ・オフィス)』のビデオクリップを見てください(http://openstax.org/l/theoffice)。ここでは、ジムはドワイトに対して、ジムのコンピュータが特定の音を出すたびにブレスミントキャンディーを期待するように条件付けしています。
古典的条件付けの一般的プロセス
ここまでで、あなたは古典的条件付けがどのように働くかを知り、いくつかの例を見てきました。それでは、そこに関わる一般的なプロセスのいくつかを調べていくことにしましょう。古典的条件付けでは、学習の初期段階は獲得として知られています。そのときには、生物が中性刺激と無条件刺激を結びつけることを学習します。獲得の過程では、中性刺激が条件反応を引き起こすようになり、最終的には中性刺激が単独で条件反応を引き起こすことのできる条件刺激になります。条件付けが起こるには、タイミングが重要です。典型的には、条件刺激と無条件刺激の提示の間は短い間隔だけがあるべきです。条件付けされる内容によっては、この間隔がわずか5秒程度であることもあります(Chance, 2009)。しかしながら、他の種類の条件付けでは、この間隔は最大で数時間に及ぶこともあります。
味覚嫌悪は、条件刺激(摂取したもの)と無条件刺激(吐き気や病気)の間に数時間の間隔が空くことのある条件付けの一種です。それがどのように進むかを、以下で見てみましょう。授業の合間に、あなたは友人と一緒にキャンパス内の屋台で簡単な昼食をとります。あなたたちはチキンカレーを分け合って、次の授業に向かいます。数時間後、あなたは吐き気を感じ、気分が悪くなりました。友人は元気であり、あなたは自分が感冒性腸炎だと判断しましたが(食べ物が原因ではありません)、あなたは味覚嫌悪を発達させてしまいます。次にあなたがレストランにいて、誰かがカレーを注文すると、あなたはすぐに気分が悪くなります。チキンカレーがあなたを病気にしたわけではないにもかかわらず、あなたは味覚嫌悪を経験しています:あなたは、一回のひどい経験の後で、ある食べ物を忌避するように条件付けされました。
このこと、つまり、たった一度の経験に基づき、しかもその出来事と負の刺激との間に長い時間の経過を伴う条件付けは、どのようにして起こるのでしょうか?味覚嫌悪の研究によると、この反応は、生物が有害な食物を避けることを素早く学習するのに役立つように設計された進化的適応である可能性が示唆されています(Garcia & Rusiniak, 1980; Garcia & Koelling, 1966)。これは、自然選択による種の存続に寄与するだけでなく、がん患者が特定の治療法によって引き起こされる吐き気をやり過ごすように支援するなどの、課題に立ち向かうための戦略を開発するのに役立つかもしれません(Holmes, 1993; Jacobsen et al., 1993; Hutton, Baracos, & Wismer, 2007; Skolin et al., 2006)。ガルシアとコーリング(Garcia & Koelling, 1966)は、味覚嫌悪が条件付けられることを示しただけでなく、学習には生物学的な制約があることも示しました。彼らの研究では、別々のグループのラットに、ある味と病気を関連付けるか、あるいは、光や音と病気を関連付けるように条件付けを行いました。その結果、味と病気のペアを与えられたラットはすべてその味を避けることを学習しましたが、光や音と病気のペアを与えられたラットは一匹も光や音を避けることを学習しませんでした。これは、古典的条件付けが、健康や福利に現実の危険を及ぼすような刺激を回避することを生物に学習させることにより、種の存続に貢献している、という考え方に対して証拠を加えました。
ロバート・レスコーラは、生物がCSからUCSを予測することをどれほど強力に学習することができるかを実証しました。たとえば、次のような2つの状況を考えてみましょう。アリのお父さんは、毎日6時になると必ず夕食をテーブルに並べます。ソラヤのお母さんは、6時に夕食を食べる日もあれば、5時に食べる日もあり、7時に食べる日もあるというように切り替えています。アリの場合、6時という時間は確実に、そして一貫して夕食を予測しているので、彼がたとえ遅い時間におやつを食べたとしても、アリは毎日6時の直前に空腹を感じ始めるでしょう。一方、ソラヤは、6時という時間は必ずしも夕食が出ることを予測しないので、6時を夕食と関連付ける可能性は低くなります。レスコーラは、イェール大学の同僚であるアラン・ワグナーとともに、条件刺激が無条件刺激の発生を予測する能力やその他の要因を考慮して、ある関連付けが学習される確率を計算するために使用することのできる数式を開発しました。これは、現在ではレスコーラ-ワグナーモデルとして知られています(Rescorla & Wagner, 1972)。
ひとたび私たちが無条件刺激と条件刺激との間に関係性を確立したら、私たちはどうやってその関係を断ち切り、犬や猫や子供が反応するのを止めるようにすることができるでしょうか?タイガーの場合、タイガーの食べ物に電動缶切りを使うのをやめて、人間の食べ物にだけ缶切りを使うようにしたらどうなるか想像してみてください。今や、タイガーは缶切りの音を聞いても、食べ物はもらえません。古典的条件付けの用語では、あなたは条件刺激を与えていますが、無条件刺激を与えていないことになります。パブロフはこのシナリオを、犬を使った実験で検証しました:彼は、犬に肉粉を与えることなく、音を鳴らしました。すると、すぐに犬は音に反応しなくなりました。消去とは、無条件刺激がもはや条件刺激とともに提示されなくなったときに、条件反応が減少することです。条件刺激だけを提示すると、犬、猫、または他の生物はどんどん反応が弱くなり、最後には反応しなくなってしまうでしょう。古典的条件付けの用語で言えば、条件反応が徐々に弱まり、消えていきます。
学習がしばらく使われず、学習されたものが休眠状態になっていると何が起きるでしょうか?私たちが先ほど議論したように、パブロフは、肉粉(無条件刺激)を伴わずにベル(条件刺激)を繰り返し提示すると、犬がベルに対して唾液を出さなくなるという消去が起こることを発見しました。しかしながら、この消去の訓練から数時間の休息の後で、パブロフがベルを鳴らすと犬は再び唾液を出すようになりました。もし、あなたの電動缶切りが壊れて、数か月間使わなかったとしたら、タイガーの行動には何が起きるだろうと思いますか?あなたがようやく缶切りを修理して、再びタイガーの食べ物を開けるのに使い始めたら、タイガーは缶切りと食べ物の関連性を思い出し、音を聞くと興奮してキッチンに駆け寄ってくるでしょう。パブロフの犬とタイガーの行動は、パブロフが自発的回復と呼んだ概念を示しています:それは、以前に消去された条件反応が、休息期間を経て再び現れることです(図6.7)。
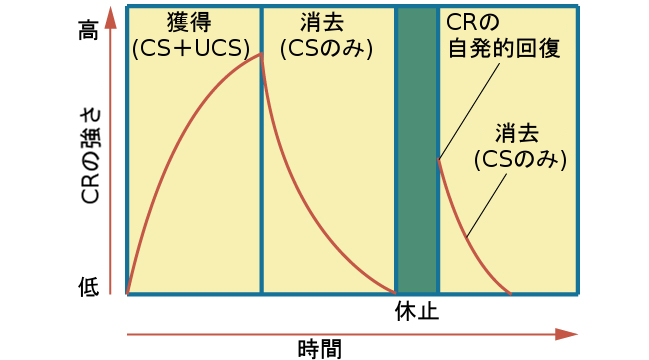
図6.7 | これは獲得、消去、および自発的回復の曲線です。上昇する曲線は、条件刺激と無条件刺激の対を繰り返すことを通じて、条件反応が急速に強くなっていく様子を示しています(獲得)。その後、曲線が下がっていくのは、条件刺激だけを提示したときに条件反応が弱くなる様子を示しています(消去)。そして、条件付けから離れたり、一時的に中断したりすると、条件反応が再び現れます(自発的回復)。
もちろん、これらのプロセスは人間にも当てはまります。たとえば、あなたが毎日キャンパスに通うときに、アイスクリームのトラックがあなたの通り道に停まっているとしましょう。あなたは日々トラックの音楽(中性刺激)が聞こえてくるので、ついに立ち止まってチョコレートアイスクリームを購入します。あなたが一口食べると(無条件刺激)、口の中によだれが出ます(無条件反応)。この学習の最初の時期は獲得として知られており、その時にあなたは中性刺激(トラックの音楽)と無条件刺激(口に入れたチョコレートアイスクリームの味)を結びつけることを始めます。獲得の間は、条件刺激と無条件刺激の対を繰り返すことを通じて、条件反応がどんどん強くなっていきます。数日(と数回のアイスクリーム)の後、あなたは、トラックの音楽を聞いた途端に(アイスクリームを口に含む前であったとしても)、口の中によだれが出始める(条件反応)ことに気づきます。そしてある日、あなたは道を歩いていました。あなたはトラックの音楽(条件刺激)を聞くと、口の中によだれが出ます(条件反応)。しかしながら、トラックのところに行ってみると、アイスクリームはすべて売り切れていました。あなたはガッカリして帰ることになります。それから数日、あなたはトラックの前を通り、音楽を聞きましたが、授業に遅れそうなのでアイスクリームを買うために立ち止まることはありませんでした。あなたは音楽を聞いても唾液が少なくなり始め、週の終わりには曲を聞いても口の中によだれが出なくなりました。これは、消去を示しています。条件刺激(トラックの音楽)だけが提示され、無条件刺激(チョコレートアイスクリームを口に入れる)が続いていないと、条件反応は弱まります。そして、週末がやって来ます。あなたは授業に出る必要がないので、トラックの前を通り過ぎることはありません。月曜日の朝が来て、あなたはいつもの道順でキャンパスに向かいます。あなたが角を曲がると、またトラックの音楽が聞こえてきます。何が起こったと思いますか?あなたの口には再びよだれが出てきます。なぜでしょうか?条件付けから離れていた後、条件反応が再び現れたのです。これは、自発的回復を示しています。
獲得と消去は、それぞれ、学習される関連性を強めたり弱めたりすることです。他の2つの学習過程(刺激分化と刺激般化)は、どの刺激が学習された反応を引き起こすかを決定することに関与しています。人間を含む動物は、複数の刺激(たとえば、脅威となる出来事を予測する音と、そうでない音)を区別して、適切な反応をする(たとえば、音が脅威であれば逃げる)必要があります。ある生物が似たようなさまざまな刺激に対して異なった形で反応をするのを学習することを刺激分化といいます。古典的条件付けでは、ある生物は条件刺激に対してのみ条件反応を示します。パブロフの犬は、餌を与えられる前に鳴る基本音と他の音(たとえば、ドアベル)を区別しました。なぜなら、他の音は餌の到来を予測するものではなかったからです。同様に、猫のタイガーは、缶切りの音と電動ミキサーの音を識別しました。電動ミキサーが動いたときでも、タイガーは食べ物をもらうことはないので、キッチンに走ってきて食べ物を探したりはしません。もうひとつの例では、がん患者のモイシャは、腫瘍医とそれ以外の医師を区別していました。彼女は、年に一度の健康診断など、他の種類の用事のために医者を訪れても、気分が悪くならないことを学びました。
一方、条件刺激に似た刺激に対して生物が条件反応を示すことを、刺激般化といいます(刺激分化の反対です)。刺激が条件刺激に似ているほど、生物は条件反応を起こしやすくなります。たとえば、電動ミキサーの音が電動缶切りの音とよく似ている場合、タイガーはその音を聞いて走ってくるかもしれません。しかし、電動ミキサーの音がした後には食べ物を与えず、電動缶切りの音がした後に一貫して食べ物を与え続ければ、タイガーはすぐに2つの音を識別できるようになります(ただし、タイガーがそれらの音を判別できるほど十分に異なっているという条件で)。もう1つの例では、モイシャは、他の腫瘍医や、担当の腫瘍医と同じ建物にいる他の医師を訪れるときには、体調を崩し続けました。
行動主義
図6.8のジョン・B・ワトソンは、行動主義の創始者と見なされています。行動主義は、パブロフの古典的条件付けの要素を取り入れた、20世紀前半に生まれた思想の一派です(Hunt, 2007)。行動の理由は無意識の中に隠されていると考えたフロイトとはまったく対照的に、ワトソンは、すべての行動は内部プロセスに関連のない単純な刺激-応答の反応として研究できるという考え方を唱えました。ワトソンは、心理学が正当な科学となるためには、内部の心的プロセスから関心を移さなければならないと主張しました。なぜなら、心的プロセスは見ることも測定することもできないからです。その代わりに、彼は、心理学が測定することのできるような外側の観察可能な行動に焦点を当てなければならないと主張しました。

図6.8 | ジョン・B・ワトソンは、人間の感情の研究において、古典的条件付けの原理を用いました。
ワトソンの考え方は、パブロフの研究に影響を受けていました。ワトソンによると、人間の行動は、動物の行動と同様に、主として条件付けられた反応の結果です。パブロフの犬を使った研究が反射の条件付けであったのに対し、ワトソンは同じ原理が人間の感情の条件付けにも拡張できると考えました(Watson, 1919)。
1920年、ワトソンはジョンズ・ホプキンス大学の心理学科の学科長を務めていました。ワトソンと大学院生のロザリー・レイナーは、アルバート坊やというニックネームがつけられている赤ん坊に関する研究を実施しました。レイナーとワトソンによるアルバート坊やに対する実験は、古典的条件付けを用いて恐怖がどのようにして条件付けられるかを実証しました。この実験を通じて、アルバート坊やは特定のものにさらされ、それらに恐怖を感じるように条件付けられました。アルバート坊やには、最初に、ウサギ、イヌ、サル、マスク、綿毛、白いラットを含む、さまざまな中性刺激が与えられました。彼は、これらのもののどれも怖がることはありませんでした。そして、ワトソンはレイナーの助けを借りて、アルバート坊やがこれらの刺激をある感情、すなわち恐怖と関連させるように条件付けました。たとえば、ワトソンがアルバート坊やに白いラットを渡すと、アルバート坊やは喜んでそれと遊びました。それからワトソンは、アルバート坊やがラットに触るたびに、アルバート坊やの頭の後ろにぶら下がっている金属棒にハンマーを打ち付けることにより、大きな音を出しました。アルバート坊やはその音に怯え(突然の大きな音に対する反射的な恐怖を示し)、泣き始めました。ワトソンはその大きな音と白いラットを繰り返し組み合わせました。やがてアルバート坊やは、白いラットだけでも怯えるようになりました。この事例の場合、UCS、CS、UCR、およびCRは何でしょうか?数日後、アルバート坊やは刺激般化を示しました。彼は、ウサギ、毛皮のコート、さらにはサンタクロースのマスクなど、他のフワフワしたものを怖がるようになりました(図6.9)。ワトソンはアルバート坊やに恐怖反応を条件付けすることに成功し、それにより感情が条件反応となり得ることを実証したのです。ワトソンの意図は、条件付けのみを通じて恐怖症(特定の物体や状況に対する持続的で過剰な恐怖感)を生み出し、それによって、恐怖症は心の中にある深くて隠された葛藤によって引き起こされるというフロイトの見解に対抗することでした。しかしながら、アルバート坊やが後年になって恐怖症を経験したという証拠はありません。アルバート坊やの母親は引っ越してしまい、実験は終了しました。ワトソンの研究は、条件付けに関する新たな洞察を提供したものの、今日の基準では非倫理的と見なされるでしょう。

図6.9 | 刺激般化により、アルバート坊やは、サンタクロースのマスクをかぶったワトソンを含め、フワフワしたものを恐れるようになりました。
学習へのリンク
ジョン・ワトソンの実験で、アルバート坊やがフワフワしたものに恐怖を感じるように条件付けされたシーンをビデオ(http://openstax.org/l/Watson1)で見て、さらに学んでください。
あなたがビデオを見る際に、アルバート坊やの反応と、条件付けの前と後でのワトソンとレイナーの刺激の与え方をよく観察してください。あなたが見たものに基づいて、あなたはこの研究者たちと同じ結論に達するでしょうか?
日常へのつながり
広告と連合学習
広告会社の経営者は、連合学習の原理を応用することに長けています。あなたがテレビで見たことのある車のコマーシャルを考えてみてください。多くのコマーシャルには魅力的なモデルが登場します。そのモデルと宣伝されている車を連想することで、あなたはその車が望ましいものとして見えるようになります(Cialdini, 2008)。あなたは、この広告手法は実際に効果があるのだろうか、と疑問に思うかもしれません。チャルディーニによると、魅力的なモデルを含む車のコマーシャルを見た男性は、同じ車の広告からモデルを除いたものを見た男性よりも、その車がより速く、より魅力的で、よりデザインが良いと評価しました(Cialdini, 2008)。
有名なスポーツ選手がスキャンダルを起こすと、広告主はすぐに契約を解除することに気付いたことはありませんか?広告主の立場からすれば、そのスポーツ選手はもはや肯定的な感情とは結び付けられません。したがって、そのスポーツ選手を無条件刺激として用いて、肯定的な感情(無条件反応)と自社製品(条件刺激)を関連付けるように公衆を条件付けることはできません。
連合学習がどのように働くかをあなたが知った上で、テレビや雑誌、インターネットなどで、このような広告の例を見つけることができるか、試してみてください。
6.3 オペラント条件付け
学習目標
この節が終わるまでに、あなたは次のことができるようになります:
- オペラント条件付けを定義する
- 強化と弱化の違いを説明する
- いくつかの強化スケジュールを区別する
この章の前の節では、古典的条件付けとして知られる連合学習のタイプに焦点を当てました。古典的条件付けでは、環境中の何かが自動的に反射を引き起こし、研究者は異なる刺激に反応するように生物を訓練する、ということを覚えておいてください。次に、私たちは、連合学習の2つ目のタイプであるオペラント条件付けへと目を向けます。オペラント条件付けでは、生物はある行動とその結果を関連付けることを学びます(表6.1)。好ましい結果は、その行動が将来的に繰り返される可能性を高めます。たとえば、ボルチモアの国立水族館のイルカのスピリットは、トレーナーが笛を吹くと空中に跳ね上がります。その結果、スピリットは魚を得ます。

表6.1
心理学者のB・F・スキナーは、古典的条件付けは反射的に引き出される既存の行動に限定されており、自転車に乗るなどの新しい行動は説明できないと考えました。彼は、そのような行動がどのようにして起こるのかについての理論を提案しました。スキナーは、行動はその行動に対して受け取る結果、つまり強化と弱化によって動機付けられると考えました。「学習とは帰結についての結果である」というスキナーの考え方は、心理学者エドワード・ソーンダイクが最初に提唱した効果の法則に基づいています。効果の法則によると、生物にとって満足をもたらす帰結が続くような行動は繰り返されやすく、不快な帰結が続くような行動は繰り返されにくいとされています(Thorndike, 1911)。基本的には、もし生物が望ましい結果をもたらす何かをすれば、その生物は再びそれを行う可能性が高くなります。もし生物が望ましい結果をもたらさないことをすれば、その生物は再びそれを行う可能性は低くなります。効果の法則の例としては、雇用があります。私たちが出勤する理由の1つ(そしてしばしば、最大の理由)は、私たちがそうすることによって給料をもらっているからです。もし私たちが給料をもらえなくなれば、たとえ仕事が好きであっても、出勤しなくなるでしょう。
スキナーは、ソーンダイクの効果の法則を自身の基盤として、動物(主にラットとハト)を使って、オペラント条件付けによって生物がどのようにして学習するかを調べる科学的実験を実施し始めました(Skinner, 1938)。彼は、動物たちをオペラント条件付けチャンバーの中に入れました。この装置は「スキナー箱」として知られるようになりました(図6.10)。スキナー箱にはレバー(ラット用)やディスク(ハト用)が入っていて、動物はそれを押したりつついたりすることで、排出口を介して餌の報酬を得ることができます。スピーカーや電灯は、特定の行動と関連付けることができます。記録装置は動物が行った反応の数を数えます。
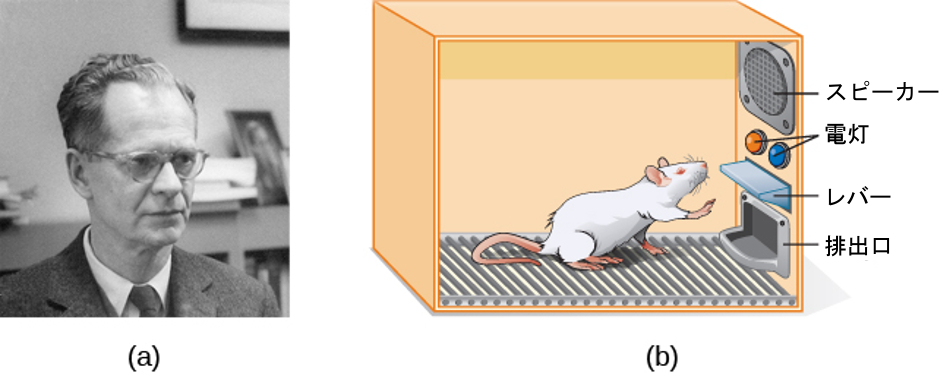
図6.10 | (a)B・F・スキナーは、行動がその帰結に応じてどのように強められたり弱められたりするかを体系的に研究するために、オペラント条件付けを開発しました。(b)スキナー箱の中では、ラットがオペラント条件付けチャンバーのレバーを押すと餌の報酬がもらえます。(credit a: modification of work by “Silly rabbit”/Wikimedia Commons)
学習へのリンク
スキナーのインタビューとハトのオペラント条件付けの実演についてのこの短いビデオ(http://openstax.org/l/skinner1)を見て、さらに学んでください。
オペラント条件付けを議論する際には、私たちはいくつかの日常的な言葉(正、負、強化、弱化)を専門的な態様で用います。オペラント条件付けでは、正と負は良い意味でも悪い意味でもありません。そうではなくて、正はあなたが何かを付け加えることを意味し、負はあなたが何かを取り去ることを意味します。強化はあなたが行動を増加させることを意味し、弱化はあなたが行動を減少させることを意味します。強化は正であることもあれば負であることもあり、弱化もまた正であることもあれば負であることもあります。すべての強化子(正または負)は、行動反応の可能性を増加させます。すべての弱化子(正または負)は、行動反応の可能性を減少させます。では、この4つの用語を組み合わせてみましょう:それは、正の強化、負の強化、正の弱化、負の弱化です(表6.2)。

表6.2
強化
人や動物に新しい行動を教えるための最も効果的な方法は、正の強化です。正の強化では、行動を増加させるために望ましい刺激を加えます。
たとえば、あなたが5歳の息子ジェロームに「部屋をきれいに片付けたら、おもちゃをあげる」と言うとします。ジェロームは、新しいお絵描きセットが欲しいので、すぐに自分の部屋を掃除します。ここで、ちょっと立ち止まってみましょう。「なぜ、期待されることをした子供に報酬を与えるべきなのだろうか?」と言う人もいるかもしれません。しかし実際には、私たちは生活の中で絶えず一貫して報酬を与えられています。給料も報酬ですし、成績が良かったり、志望校に合格したりすることも報酬です。良い仕事をして表彰されたり、運転免許試験に合格したりすることも報酬です。学習ツールとしての正の強化は非常に効果的です。読書成績が平均未満の学区で達成度を上げる最も効果的な方法のひとつは、子供たちにお金を払って読ませることだということがわかっています。具体的には、ダラスの小学2年生を対象に、本を読み、その本についての短いクイズに合格するたびに2ドルが支払われました。その結果は、読解力の大幅な向上でした(Fryer, 2010)。このプログラムについて、あなたはどう思いますか?もしスキナーが現在に生きていたら、彼はこのプログラムを素晴らしいアイデアだと思うでしょう。彼は、学校で生徒の行動に影響を与えるためにオペラント条件付けの原理を使うことを強く推奨していました。実際、彼は、スキナー箱に加えて、学習の小さな段階に報酬を与えるように設計されたティーチング・マシンと呼ばれるものを考案しました(Skinner, 1961)。これはコンピュータ支援学習の初期の先駆けです。彼のティーチング・マシンは、生徒が学校のさまざまな教科を学習する際に、その知識をテストするものでした。もし生徒が質問に正しく答えれば、彼らはすぐに正の強化を受けて継続することができます。もし彼らが正しく答えられない場合、彼らはどのような強化も受け取りません。ここでの考え方は、生徒は次の機会において強化を受ける可能性を高めるために、さらに時間をかけて教材を学習するであろうというものです(Skinner, 1961)。
負の強化では、望ましくない刺激を取り除くことで行動を増加させます。たとえば、自動車メーカーは、シートベルトシステムに負の強化の原理を利用しており、あなたがシートベルトを締めるまで「ピッ、ピッ、ピッ」という音が鳴ります。あなたが望ましい行動をとると、その不快な音は止まり、あなたが将来シートベルトを締める可能性が高まります。負の強化は馬の訓練にもよく使われます。騎手は手綱を引いたり、足を押し付けたりして圧力をかけ、馬がターンやスピードアップなどの望ましい行動をしたら圧力を取り除きます。その圧力は、馬が取り除きたいと望むような負の刺激です。
弱化
多くの人がオペラント条件付けにおける負の強化と弱化を混同していますが、それらは2つの非常に異なるメカニズムです。強化は、たとえそれが負であっても、常に行動を増加させることを思い出してください。それに対して弱化は、常に行動を減少させるものです。正の弱化では、望ましくない刺激を加えて行動を減少させます。正の弱化の例としては、生徒が授業中にテキストメッセージを送るのをやめさせるために生徒を叱ることが挙げられます。この場合、行動(授業中にテキストメッセージを送る)を減少させるために、刺激(叱責)が加えられます。負の弱化では、行動を減少させるために好ましい刺激を取り除きます。たとえば、子供が悪さをしたときに、親はお気に入りのおもちゃを取り上げることがあります。この場合、行動を減少させるために、刺激(おもちゃ)が取り除かれます。
弱化は、特にそれが即時のものであるときには、望ましくない行動を減少させるための1つの方法となります。たとえば、あなたの4歳の息子、ブランドンが弟を叩いたとします。あなたはブランドンに「これからは弟を叩かない」と100回書かせます(正の弱化)。そうすれば、彼はおそらくこの行動を繰り返さないでしょう。このような戦略は現代では一般的ですが、昔の子供たちはしばしば尻を叩くような体罰を受けることがありました。子供に対して体罰を使うことにはいくつかの欠点があることを知っておくことが重要です。まず、体罰によって恐怖を教えてしまうことになるかもしれません。ブランドンは道を怖がるようになるかもしれませんが、彼はまた、弱化を与えた人、つまり親であるあなたを怖がるようになるかもしれません。同様に、教師から体罰を受けた子供は、教師を恐れるようになり、学校を避けようとするかもしれません(Gershoff et al., 2010)。そのため、米国のほとんどの学校が体罰を禁止しています。第二に、体罰によって子供がより攻撃的になり、反社会的な行動や非行に走りやすくなる可能性があります(Gershoff, 2002)。子供は、親が怒ったりイライラしたりしたときに尻叩きに頼るのを見て、今度は自分が怒ったりイライラしたりしたときに同じ行動をとるようになるかもしれません。たとえば、ブレンダが悪いことをしてあなたが怒ったときに、あなたがブレンダを叩くので、ブレンダは友達がおもちゃを分けてくれないと友達を叩くようになるかもしれません。
いくつかの場合では正の弱化が有効になり得ますが、スキナーは、弱化の使用は起こりうる悪影響と照らし合わせて判断すべきだと示唆しました。現在の心理学者や子育ての専門家は、弱化よりも強化を重視しています。彼らは、子供が何か良いことをしているのを見つけて、それに対して報酬を与えることを推奨しています。
シェーピング
スキナーは、オペラント条件付けの実験の中で、シェーピングというアプローチをしばしば用いました。シェーピングでは、私たちは、標的とする行動だけに報酬を与えるのではなく、標的とする行動に漸次接近するものに報酬を与えます。なぜシェーピングが必要なのでしょうか?強化が働くためには、生物がまず行動を示さなければならないことを思い出してください。シェーピングが必要なのは、生物が最も単純な行動以外のものを自発的に示す可能性が極めて低いからです。シェーピングでは、行動を小さな達成可能なステップに分解します。このプロセスにおいて用いられる具体的なステップは以下の通りです:
- 望ましい行動に類似した反応を強化します。
- そして、望ましい行動によりよく類似した反応を強化します。以前に強化した反応はもう強化しません。
- 次に、望ましい行動にさらによりよく類似した反応を強化し始めます。
- 望ましい行動にだんだんと近接するものを強化していきます。
- 最後に、望ましい行動のみを強化します。
シェーピングは、複雑な行動や一連の行動を教える際にしばしば使われます。スキナーはシェーピングを使って、ハトにスキナー箱の中の円盤をつつくといった比較的単純な行動だけでなく、円を描くように回る、8の字を描くように歩く、さらには卓球をするといった多くの珍しく楽しい行動を教えました。この手法は、現在でも動物のトレーナーによって、一般的に使われています。シェーピングで重要なのは、刺激分化です。パブロフの犬のことを思い出してください。彼は、ベルの音に反応し、似たような音には反応しないように犬を訓練しました。この分化はオペラント条件付けや行動のシェーピングにおいても重要です。
学習へのリンク
スキナーのハトが卓球をしている短いビデオ(http://openstax.org/l/pingpong)を見て、さらに学んでください。
シェーピングが動物に行動を教えるのに有効であることは容易に理解できますが、シェーピングは人間に対してはどのように作用するのでしょうか?子供が自分の部屋をきれいにできるようになることを目標にしている親の場合を考えてみましょう。彼らはシェーピングを使って、子供が目標に向かって段階的に学習するのを助けます。全てのタスクを実行するのではなく、親はステップを設定し、それぞれのステップで強化を行います。まず、子供はおもちゃを1つ片付けます。第二に、おもちゃを5つ片付けます。第三は、10個のおもちゃを拾い上げるか、本や服を片付けるかを選択します。第四は、2つのおもちゃ以外をすべて片付けます。最後に、その子は自分の部屋全体をきれいにします。
一次強化子と二次強化子
ステッカー、褒め言葉、お金、おもちゃなどの報酬は、学習を強化するために使用することができます。もう一度、スキナーのラットに戻りましょう。ラットはどのようにしてスキナー箱の中のレバーを押すことを学んだのでしょうか?ラットは、レバーを押すたびに食べ物により報酬が与えられました。動物にとっては、食べ物は明らかに強化子です。
人間にとっては何が良い強化子となるでしょうか?あなたの子供のクリスにとっては、それは、部屋をきれいにするとおもちゃがもらえるという約束でした。サッカー選手のシドニーはどうでしょうか?もし、シドニーがゴールを決めるたびにあなたがキャンディーをあげていたとしたら、あなたは一次強化子を使っていることになります。一次強化子とは、内在的に強化の性質を持った強化子のことです。この種の強化子は学習されません。水、食べ物、睡眠、住処、性交、触覚などが一次強化子です。また、快楽も一次強化子です。生物はこれらのものに対する欲求を失うことはありません。ほとんどの人にとって、とても暑い日に冷たい湖に飛び込むことは強化するものであり、冷たい湖は内在的に強化するものです。水は人を冷やす(身体的な必要性)だけでなく、喜びをもたらします。
二次強化子には内在的な価値はなく、一次強化子と結びついたときにのみ強化の性質を発揮します。たとえば、シドニーがゴールを決めるたびにあなたが「すごいシュート!」と声をかけるときのように、褒め言葉は、愛情と結びついて、二次強化子の一例となります。もう1つの例であるお金は、あなたが基本的な欲求を満たすもの(食糧、水、住処などの一次強化子)や他の二次強化子を買うために使うことができて初めて価値を持ちます。もしあなたが太平洋の真ん中の離島にいて、山のようなお金を持っていたとしても、使うことができなければ、そのお金は役に立ちません。行動表に貼ってあるステッカーはどうでしょうか?これも二次強化子です。
ステッカー表のシールの代わりに、トークンを使うこともあります。トークンも二次強化子ですが、これを報酬や賞品と交換することができます。トークンエコノミーとして知られる行動管理システム全体が、このようなトークンによる強化子の使用を中心に構築されています。トークンエコノミーは、学校、刑務所、精神病院など、さまざまな環境で行動を修正するのに非常に効果的であることがわかっています。たとえば、キャンジとダリーによる研究では、自閉症の児童のグループにおいて、トークンエコノミーを使用することで、適切な社会的行動が増加し、不適切な行動が減少することがわかりました(Cangi & Daly, 2013)。自閉症の子供たちは、つねったり叩いたりするような問題を起こす行動をとる傾向があります。この研究における子供たちが適切な行動(叩いたり、つねったりしない)をとったときには、彼らは「静かな手」というトークンを受け取りました。彼らが叩いたり、つねったりすると、トークンを失います。子供たちは、指定された量のトークンを遊びの時間に交換することができました。
日常へのつながり
子供における行動変容
親や教師は、子供の行動を変えるために、しばしば行動変容を用います。行動変容とは、オペラント条件付けの原理を用いて行動を変え、望ましくない行動をより社会的に受け入れられる行動に切り替えるものです。一部の教師や保護者は、いくつかの行動を列挙したステッカー表を作成します(図6.11)。ステッカー表は、本文で説明したように、トークンエコノミーの一形態です。子供たちは行動をするたびにシールをもらい、一定の数のシールをもらうと、賞品、つまり強化子をもらうことができます。目標は、許容可能な行動を増やし、不作法な振る舞いを減らすことです。弱化を使うのではなく、望ましい行動を強化することが最善であることを覚えておいてください。教室では、教師は、生徒が手を挙げること、廊下を静かに歩くこと、宿題を提出することなど、さまざまな行動を強化することができます。家庭では、親が行動表を作成して、おもちゃを片付けたり、歯を磨いたり、夕食の用意を手伝ったりしたときに子供に報酬を与えることができるかもしれません。行動変容が効果的であるためには、強化が行動と結びついている必要があります。強化は、子供にとって重要なものであり、一貫して行われなければなりません。

図6.11 | ステッカー表は、正の強化の一形態であり、行動変容のための道具です。この子供が望ましい行動を示して一定数のシールを獲得したら、彼女はアイスクリーム屋に行くという報酬が与えられます。(credit: Abigail Batchelder)
タイムアウトは、子供の行動変容においてよく使われるもう1つの手法です。これは、負の弱化の原則に基づいて作用します。子供が望ましくない行動をしたときには、その子は身近な望ましい活動から外されます(図6.12)。たとえば、ソフィアと弟のマリオが積み木で遊んでいるとします。ソフィアが弟に向かって積み木を投げたので、あなたは彼女に対して「今度やったらタイムアウトにするよ」と注意します。数分後、ソフィアはまたマリオに積み木を投げつけました。あなたはソフィアを数分間部屋の外に出しました。ソフィアは戻ってくると、積み木を投げることはありませんでした。
行動変容の手法としてタイムアウトを導入することを計画している場合、あなたが知っておくべき重要なポイントがいくつかあります。第一に、子供が望ましい活動から外され、より望ましくない場所に置かれていることを確認してください。もしその活動が子供にとって望ましくないものであれば、子供にとってはその活動から外される方が楽しいので、この手法は逆効果になります。第二に、タイムアウトの長さが重要です。一般的には、子供の年齢1歳につき1分が目安です。ソフィアは5歳なので、彼女は5分間のタイムアウトを過ごすことになります。タイマーを設定しておけば、子供は自分がどれだけの長さのタイムアウトを過ごさなければならないかを知ることができます。最後に、保育者として、タイムアウトを行う際に、いくつかの指針を心に留めておいてください:子供にタイムアウトを指示するときは落ち着いてください。タイムアウト中は子供を無視してください(保育者が注意を向けていることは、いたずらを強化することがあるからです)。タイムアウトが終わったら子供を抱きしめたり、優しい言葉をかけたりしてください。

図6.12 | タイムアウトは、保護者が行う負の弱化の一般的な形態です。子供が悪さをしたとき、望ましくない行動を減らすために、その子は望ましい活動から外されます。たとえば、(a)ある子供が友達と遊び場で遊んでいて、他の子供を押してしまった場合、(b)悪さをした子供は短時間、その活動から外されます。(credit a: modification of work by Simone Ramella; credit b: modification of work by “Spring Dew”/Flickr)
強化スケジュール
人や動物に行動を教える最善の方法は、正の強化を用いることだというのを思い出してください。たとえば、スキナーは正の強化を使って、ラットにスキナー箱の中のレバーを押すことを教えました。最初は、ラットが箱の中を探索しているときに、行き当たりばったりにレバーを押して、餌のペレットが出てきたのかもしれません。その餌を食べた後、お腹を空かせたラットはどうしたと思いますか?ラットは、もう一度レバーを押して、また餌のペレットを受け取りました。ラットがレバーを押すたびに餌のペレットが出てきました。生物が行動を起こすたびに強化子を受け取ることを連続強化と言います。この強化スケジュールは、誰かに行動を教えるのに最も手っ取り早い方法であり、新しい行動を訓練するのに特に効果的です。この章の前半でお座りを学んでいた犬のことを振り返ってみましょう。今、犬がお座りするたびに、あなたはおやつを与えます。ここではタイミングが重要です:犬が標的行動(お座り)と帰結(おやつをもらう)を関連付けることができるように、犬がお座りした直後にあなたが強化子を提示するならば、最も成功するでしょう。
学習へのリンク
獣医師のソフィア・イン博士が、上記のステップを使って犬の行動を形成しているビデオクリップ(http://openstax.org/l/sueyin)を見て、さらに学んでください。
ある行動が訓練されると、研究者やトレーナーはしばしば別のタイプの強化スケジュールである部分強化に目を向けます。部分強化(間欠強化とも呼ばれます)では、人や動物が望ましい行動をするたびに強化されるわけではありません。部分強化のスケジュールにはいくつかの異なるタイプがあります(表6.3)。これらのスケジュールは、固定か可変か、そして、間隔か比率か、として記述されます。固定とは、強化の間の反応の数、または強化の間の時間の量が設定されており、変化しないことを指します。可変とは、強化の間の反応の数、または強化の間の時間の量がばらつく、または変化することを指します。間隔は強化の間の時間に基づいたスケジュールを意味し、比率は強化の間の反応の数に基づいたスケジュールを意味します。
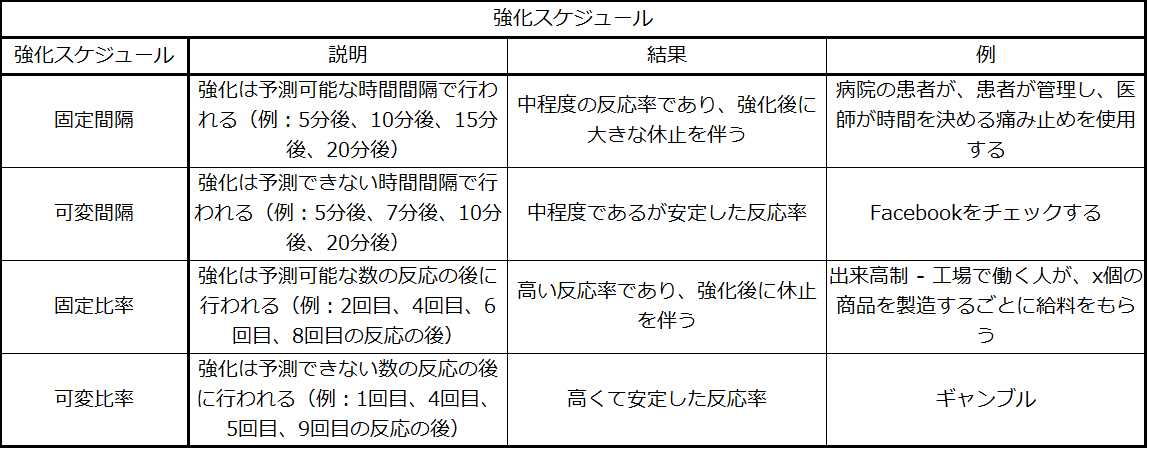
表6.3
では、これら4つの用語を組み合わせてみましょう。固定間隔の強化スケジュールとは、既定の量の時間が経過した後に行動に対して報酬が与えられることです。たとえば、ジューンは病院で大手術を受けました。回復の間、彼女は痛みを経験することが予想され、痛みを和らげるための処方薬が必要になります。ジューンは、患者管理型の鎮痛剤を静脈内点滴で投与されます。医師は、1時間に1回という制限を設けています。ジューンは痛みがつらくなったらボタンを押して、薬の1回分の投与を受けます。報酬(痛みの緩和)は固定された間隔でしか発生しないので、報酬が与えられないときに行動を示す意味はありません。
可変間隔の強化スケジュールでは、人や動物は、予測できないさまざまな時間の量に基づいて強化を受け取ります。たとえば、マニュエルがファーストフードレストランのマネージャーだとします。時々、品質管理部門の人がマニュエルのレストランにやってきます。もし店内が清潔で、サービスが早ければ、そのシフトの全員が20ドルのボーナスを得ることができます。マニュエルはいつ品質管理担当者が現れるかわからないので、彼は常にレストランを清潔に保ち、従業員が迅速で丁寧なサービスを提供するように心がけています。マニュエルは、従業員がボーナスを獲得することを望んでいるので、迅速なサービスとレストランの清潔さを保つことに関する彼の生産性は安定しています。
固定比率の強化スケジュールでは、行動に報酬が与えられる前に発生しなければならない反応の数が設定されています。カーラはメガネ店でメガネを販売しており、彼女はメガネを1つ売るたびに手数料を得ます。彼女は、手数料を増やすために、度付きサングラスや予備のメガネを含めて、より多くのメガネを人々に売ろうとします。彼女はその人が本当に度付きのサングラスを必要としているかどうかは気にしません。カーラはただ自分のボーナスを望んでいます。カーラの手数料は品質に基づくものではなく、販売数にのみ基づくものなので、カーラが販売する商品の品質は重要ではありません。このような仕事ぶりの質の違いは、どの強化方法が特定の状況にとって最も適しているかを判断するのに役立ちます。固定比率は生産物の量を最適化するのに適している一方で、報酬が量に基づいていない固定間隔では、生産物の質を高めることができます。
可変比率の強化スケジュールでは、報酬を得るために必要な反応の数が変化します。これは最も強力な部分強化スケジュールです。可変比率の強化スケジュールの例は、ギャンブルです。普段は賢くて倹約家の女性であるサラが、初めてラスベガスを訪れたとします。彼女はギャンブラーではありませんが、興味本位でスロットマシンに25セントを入れ、さらにもう1枚、もう1枚と入れていきます。何も起こりません。2ドル分の25セント硬貨を入れた後、彼女の好奇心は薄れ、もうやめようと思っていました。しかし、その時、マシンが光り、ベルが鳴り、サラは50枚の25セント硬貨を取り戻したのです。「そうこなくっちゃ!」サラは再び興味を持って25セント硬貨を挿入し、数分後にはすべての利益を使い果たして、10ドルの赤字になってしまいました。もうやめたほうが賢明かもしれない。しかし、彼女はスロットマシンにお金を入れ続けています。なぜなら、彼女は、次の強化がいつ来るかわからないからです。彼女は、次の25セントで50ドル、100ドル、あるいはそれ以上を獲得できると考え続けています。ほとんどの種類のギャンブルの強化スケジュールは可変比率のスケジュールであるため、人々は次の機会に大勝ちすることを期待して挑戦し続けます。これが、ギャンブルが非常に嗜癖性が高く、消去に対して抵抗力のある理由の1つです。
オペラント条件付けでは、強化された行動の消去は、強化が停止した後のある時点で起こります。それが起こる速度は強化スケジュールによって異なります。可変比率のスケジュールでは、上述のように消去のポイントは非常にゆっくりと訪れます。しかし、それ以外の強化スケジュールでは、消去が早く訪れる場合があります。たとえば、ジューンが痛み止めの薬のボタンを、医師が許可した決められた時間の前に押した場合、薬は投与されません。彼女は固定間隔の強化スケジュール(1時間ごとに投薬)によっているので、強化が予想される時間に来ないとすぐに消去が起こります。強化スケジュールの中では、可変比率が最も生産性が高く、最も消去しにくいスケジュールです。固定間隔は、最も生産性が低く、最も消去しやすいスケジュールです(図6.13)。

図6.13 | 4つの強化スケジュールは異なる反応パターンをもたらします。可変比率のスケジュールは予測不可能であり、高い安定した反応率が得られ、強化後の休止が(たとえあったとしても)ほとんどありません(例:ギャンブラー)。固定比率のスケジュールは予測可能であり、高い反応率が得られ、強化後に短い休止があります(例:メガネの販売員)。可変間隔のスケジュールは予測不可能であり、中程度の安定した反応率が得られます(例:レストランの店長)。固定間隔のスケジュールでは、強化後にかなりの休止を置いて、帆立貝のような形の反応パターンが得られます(例:手術患者)。
概念をつなげてみよう
ギャンブルと脳
スキナー(Skinner, 1953)は、「ギャンブル場は、何の見返りもなしに利用者がお金を差し出すように言いくるめることができないならば、利用者のお金の一部を可変比率のスケジュールで返却することによって、同じ効果を得ることができる」(p.397)と述べています。
スキナーは、ギャンブルを例にとって、強化がない期間が長くても行動を維持することについての可変比率の強化スケジュールの威力を示しています。実際、スキナーはギャンブル嗜癖についての自身の知識に自信があったので、ハトを病的なギャンブラーに変えることができるとさえ主張していました(“Skinner’s Utopia,” 1971)。確かに、可変比率のスケジュールでは、行動がかなり持続します。親が一度でも行動を認めてしまった場合における、子供が駄々をこねる頻度について想像してみてください。たまに報酬があると、その行動を止めるのはほとんど不可能になります。
ラットを使った最近の研究では、可変比率のスケジュールでの訓練だけで病的なギャンブルを引き起こすというスキナーの考え方を支持することはできませんでした(Laskowski et al., 2019)。しかしながら、他の研究では、ギャンブルはほとんどの嗜癖性薬物と同じように脳に作用するようなので、脳の化学的性質と強化スケジュールの組み合わせによってギャンブルの問題につながる可能性が示唆されています(図6.14)。具体的には、現代の研究では、ギャンブルと、神経伝達物質(脳内化学物質)のドーパミンを使用する脳の報酬中枢の活性化との関連性が示されています(Murch & Clark, 2016)。興味深いことに、ギャンブラーは、脳内でのドーパミンの「ラッシュ(ほとばしり)」を経験するためには、勝つ必要さえありません。「ニアミス」、つまり勝ちそうになったが実際には勝てなかった場合も、ドーパミンを使う腹側線条体やその他の脳内の報酬中枢の活動が高まることがわかっています(Chase & Clark, 2010)。これらの脳への影響は、コカインやヘロインなどの嗜癖性薬物によってもたらされるものとほぼ同じです(Murch & Clark, 2016)。これらの類似性を示す脳科学的証拠に基づいて、DSM-5ではギャンブルを嗜癖と見なしていますが、DSMの以前のバージョンではギャンブルを衝動制御障害として分類していました。

図6.14 | いくつかの研究は、病的ギャンブラーが、ストレスに関連し、興奮やスリルを感じたときに分泌されるノルエピネフリンというホルモンの異常な低さを補うためにギャンブルを利用していることを示唆しています。(credit: Ted Murphy)
ギャンブルには、ドーパミンに加えて、ノルエピネフリンやセロトニンを含む他の神経伝達物質が関与しているようでもあります(Potenza, 2013)。ノルエピネフリンは、人がストレス、興奮、またはスリルを感じたときに分泌されます。病的ギャンブラーは、この神経伝達物質のレベルを上げるためにギャンブルを利用しているのかもしれません。セロトニンの欠乏は、ギャンブル嗜癖を含む強迫行動の原因になることもあります(Potenza, 2013)。
これらの研究が示唆しているように、病的ギャンブラーの脳は他の人の脳とは異なっており、おそらくその違いが何らかの形でギャンブル嗜癖につながっているのかもしれません。しかしながら、真の実験を行うことが不可能であるため、真相を突き止めることは非常に困難です(無作為に割り当てられた参加者を問題のあるギャンブラーに変えようとすることは、非倫理的でしょう)。そのため、実際には、因果関係は逆方向に動いているのかもしれません。もしかしたら、ギャンブルという行為が、一部のギャンブラーの脳内の神経伝達物質のレベルを何らかの形で変化させているのかもしれません。また、何らかの見落とされていた因子、すなわち交絡変数が、ギャンブル嗜癖と脳内化学物質の違いの両方に関与している可能性もあります。
認知と潜在学習
ワトソンやスキナーのような厳格な行動主義者は、認知(思考や期待など)よりも行動を研究することに専念しました。実際、スキナーは、認知が重要ではないという考え方をあまりにも頑強に持っていたため、彼の考え方は急進的行動主義と見なされていました。スキナーは心を「ブラックボックス」、すなわち完全に不可知のものであり、したがって、研究すべきではないものと考えていました。しかしながら、もう1人の行動主義者エドワード・C・トールマンは違う意見を持っていました。トールマンはラットを使った実験で、生物は即座に強化を受けなくても学習できることを実証しました(Tolman & Honzik, 1930; Tolman, Ritchie, & Kalish, 1946)。この発見は、強化が即座に行われなければ学習は起こらないという当時の一般的な考え方とは相反するものであり、学習には認知的な側面があることを示唆していました。
実験では、トールマンは空腹のラットを迷路に入れて、迷路の出口を見つけても報酬が得られないようにしました。彼はまた、迷路の最後にある餌で報酬が与えられる比較群も研究しました。強化なしのラットは、迷路を探索するうちに、心の中での迷路の配置の図である認知地図を発達させました(図6.15)。強化なしで10回の迷路の探索を行った後、迷路の端にあるゴールの箱に餌を置きました。ラットは餌に気づくとすぐに、迷路の中を素早く(報酬としてずっと餌を与えられていた比較群と同じくらい素早く)、通り抜けることができました。これは潜在学習として知られています。それは、学習は行われているものの、それを実証する理由がない限り、行動としては観察できないような学習のことです。
図6.15 | 心理学者のエドワード・トールマンは、ラットが認知地図を使って迷路を進むことを発見しました。あなたは、ビデオゲームで複数の階層を動き回った経験はありますか?あなたは、左に曲がったり、右に曲がったり、あるいは上に移動したり、下に移動したりしたときに学習をしました。その場合、あなたは、迷路の中のラットと同じように、認知地図を頼りにしていたのです。(credit: modification of work by “FutUndBeidl”/Flickr)
潜在学習は人間にも起こります。子供は親の行動を見ることによって学習して、後日、学習した内容が必要になったときに初めてそれを発揮することがあります。たとえば、ラヴィのお父さんが、彼を毎日学校まで車で送ってくれたとします。この途上で、ラヴィは自分の家から学校までの道のりを学びますが、自分で運転することがないので、道のりを学んだことを示す機会がありませんでした。ある朝、ラヴィのお父さんは会議のために早く家を出なければならず、彼を学校まで車で送ることができませんでした。代わりにラヴィは、お父さんが車で行くのと同じ道順を自転車でたどります。これは潜在学習を示しています。ラヴィは学校までの道のりを学んでいましたが、その知識を以前に示す必要はなかったのです。
日常へのつながり
この場所はまるで迷路のようだ
あなたはこれまでに、建物の中で迷子になり、どうやって戻ったらいいかがわからなくなったことはありませんか?それはイライラすることですが、あなただけのことではありません。誰もが一度や二度は、博物館や病院、大学の図書館などのような場所で迷子になったことがあるはずです。トールマンのラットが迷路の認知地図を作ったように、私たちは新しい場所に行くたびに、その場所についての心的表象、つまり認知地図を作ります。しかしながら、建物の中には、似たような場所がたくさんあったり、見通しが悪かったりするために、わかりにくいものがあります。そのため、角の先に何があるのかを予測したり、建物から出るために左に曲がるのか右に曲がるのかを判断したりするのが難しいことがしばしばあります。心理学者のローラ・カールソン(Carlson, 2010)は、私たちが自分の認知地図に何を配置するかが、環境の中での移動の成功に影響すると示唆しています。彼女は、建物に入るときに、壁にかかっている絵、噴水、像、エスカレーターなどの特定の特徴に注意を払うことで、認知地図に情報が追加され、後に建物から出る道を探すときに利用できると指摘しています。
学習へのリンク
カールソンの認知地図と建物内の移動に関する研究についてのビデオ(http://openstax.org/l/carlsonmaps)を見て、さらに学んでください。
6.4 観察学習(モデリング)
学習目標
この節が終わるまでに、あなたは次のことができるようになります:
- 観察学習を定義する
- モデリングのプロセスの段階について議論する
- 観察学習の向社会的効果と反社会的効果を説明する
この章の以前の節では、連合学習の一形態である古典的条件付けとオペラント条件付けに焦点を当てました。観察学習では、私たちは、他の人を見て、その人が行うことや言うことを模倣する、すなわちモデルにすることによって学習します。たとえば、あなたは何かのやり方を紹介している動画を探すためにYouTubeを見たことはありますか?模倣された行動を行っている人は、モデルと呼ばれます。この模倣学習には、ミラーニューロンと呼ばれる特定の種類のニューロンが関与していることが研究で示唆されています(Hickock, 2010; Rizzolatti, Fadiga, Fogassi, & Gallese, 2002; Rizzolatti, Fogassi, & Gallese, 2006)。
人間や他の動物には、観察学習の能力があります。あなたがこれから見ていくように、「サルが見れば、サルが真似をする」という言葉はまさにその通りです(図6.16)。他の動物についても同じことが言えます。たとえば、チンパンジーの社会学習についてのある研究では、研究者は、飼育している2つのグループのチンパンジーに、ストロー付きのパックジュースを与えました。最初のグループは、ストローをジュースのパックに浸して、ストローの先にある少量のジュースを吸いました。2番目のグループは、ストローを直接吸って、より多くのジュースを得ました。最初のグループである「浸すチンパンジー」が、2番目のグループである「吸うチンパンジー」を観察したとき、何が起こったと思いますか?最初のグループの「浸すチンパンジー」たちは、全員がストローで直接吸うように切り替えました。他のチンパンジーを観察し、彼らの行動をモデルにするだけで、この方法がより効率的にジュースを得る方法であることを学んだのです(Yamamoto, Humle, and Tanaka, 2013)。

図6.16 | このクモザルは、人間がモデルとなっている行動を見ることにより、ペットボトルから水を飲むことを学習しました。(credit: U.S. Air Force, Senior Airman Kasey Close)
模倣は人間の方がはるかにわかりやすいですが、模倣は本当に追従の最も誠実な形態なのでしょうか?クレアの観察学習の経験について考えてみましょう。クレアの9歳の息子ジェイは、学校で問題を起こし、家では反抗的な態度をとっていました。クレアの2人の兄弟はどちらも刑務所におり、彼女は、ジェイが自分の兄弟のようになってしまうのではないかと心配していました。ある日、学校でまたもや問題を起こし、教師からも否定的な手紙が送られてきて、途方に暮れたクレアは、息子をベルトで叩いて行儀よくさせました。その夜、子供たちを寝かしつけるとき、クレアは4歳の娘アンナがベルトを持って自分のテディベアに鞭打つのを目撃しました。クレアは、アンナが母親の真似をしていることに気づき、愕然としました。その時、クレアは子供たちを別の方法でしつけたいと思いました。
ラットを使った実験で学習に認知的要素があることを示唆したトールマンのように、心理学者のアルバート・バンデューラの学習についての考え方は、厳格な行動主義者のものとは異なっていました。バンデューラと他の研究者たちは、認知プロセスを考慮した社会的学習理論という行動主義の一区分を提唱しました。バンデューラによれば、純粋な行動主義では、なぜ外部からの強化がないのに学習が行われるのかを説明することができません。バンデューラは、学習には内部の心的状態も役割を持っていなければならないと考え、観察学習には模倣以上のものが含まれるとしました。模倣では、人はモデルが行うことを単純にコピーします。観察学習はもっと複雑です。ラフランソワ(Lefrançois, 2012)によると、観察学習が起こり得るいくつかの方法があります:
- あなたは新しい反応を学びます。同僚が遅刻して上司に怒られているのを見た後、あなたは自分が遅刻しないように10分早く家を出ることを始めます。
- あなたはモデルに起こったことに応じて、そのモデルを模倣するかどうかを選択します。ジュリアンと彼の父親のことを覚えていますか?サーフィンを習うとき、ジュリアンは父親がサーフボードの上でうまく立ち上がるのを見て、同じことをしようとするかもしれません。一方、ジュリアンは、父親がストーブで火傷するのを見て、熱いストーブに触ってはいけないと学ぶかもしれません。
- あなたは他の状況に適用できる一般的なルールを学びます。
バンデューラは、生きたモデル、言葉のモデル、象徴的モデルという3種類のモデルを特定しています。生きたモデルとは、ジュリアンにやり方を見せるためにベンがサーフボードの上に立ち上がったときのような、生で行動を実演して見せるものです。言葉による指導モデルは、行動を行うのではなく、サッカーのコーチが若い選手に「つま先ではなく、足の側面でボールを蹴るように」と指示するように、行動を説明したり言い表したりするものです。象徴的モデルは、本、映画、テレビ番組、ビデオゲーム、インターネットなどにおいて行動を示す架空の人物や実在の人物のことです(図6.17)。

図6.17 | (a)ヨガの生徒は、ヨガインストラクターが生徒のために正しい姿勢と動きを実演しているのを観察することによって学びます(生きたモデル)。(b)学習が起きるためには、モデルが必ずしも存在しなければいけないわけではありません:この子供は、象徴的モデリングを通じて、テレビで誰かが実演するのを見て行動を学ぶことができます。(credit a: modification of work by Tony Cecala; credit b: modification of work by Andrew Hyde)
学習へのリンク
マーケティングや広告の世界では、潜在学習やモデリングがよく使われています。デレク・ジーター(http://openstax.org/l/jeter)が出演するこのフォードのコマーシャルは、ニューヨーク、ニュージャージー、コネチカットの各地域で数か月にわたって流されました。ジーターは、ニューヨーク・ヤンキースの野球選手で、数々の賞を受賞しています。このコマーシャルは、ジーターが非常に有名なスポーツ選手であるような、この国の中の一部地域で放映されました。彼は裕福であり、非常に誠実で格好良いと考えられています。彼を広告に登場させることによって、広告主はどのようなメッセージを送っているのでしょうか?また、そのメッセージはどれだけ効果的だと思いますか?
モデリングプロセスの段階
もちろん、私たちはモデルを観察しただけでは行動を学ぶことはありません。バンデューラは、学習を成功させるために従わなければならないモデリングのプロセスを、具体的な段階に分けて説明しています:その段階は、注意、保持、再生、および動機付けです。まず、あなたはモデルが何をしているかに注目しなければなりません—つまり、あなたは注意を払わなければなりません。次に、あなたは、自分が観察したことを保持する、すなわち記憶することができなければなりません。これが保持です。そして、あなたは、自分が観察して記憶にとどめた行動を実行することができなければなりません。これが再生です。最後に、あなたは動機付けを有していなければなりません。あなたは、その行動を真似したいと望む必要があり、あなたが動機付けられているかどうかは、モデルに何が起こったかによって決まります。もし、モデルがその行動のために強化されているのを見れば、あなたは真似したいという動機付けが高まります。これは代理強化として知られています。一方、もしモデルが弱化されているのを観察した場合は、あなたは真似する動機付けが下がります。これは代理弱化と呼ばれます。たとえば、以下の場面を想像してみてください。4歳のアリソンは、姉のケイトリンが母親の化粧品で遊んでいるのを見て、母親が部屋に入ってきたときにケイトリンがタイムアウトをされるのを見ました。母親が部屋を出た後、アリソンは化粧品で遊びたいと思いましたが、母親からタイムアウトをされたくありませんでした。彼女は何をしたと思いますか?あなたが新しい行動を実際に示した後、その行動を繰り返すかどうかは、あなたが受けた強化によって影響されます。
バンデューラはモデリング行動、特に大人の攻撃的・暴力的な行動を子供がモデリングすることについて研究しました(Bandura, Ross, & Ross, 1961)。彼は、ボボ人形と呼ぶ5フィートの空気で膨らませた人形を使って実験を行いました。この実験では、子供の攻撃的な行動は、教える人の行動が弱化されたかどうかによって影響を受けました。あるシナリオでは、子供が見ている中で、教える人が人形を叩いたり、投げたり、さらには殴ったりといった攻撃的な行動をとりました。教える人の行動に対する子供たちの反応は2種類ありました。教える人が悪い行いのために罰せられると、子供たちは教える人がやっていたような行動をとる傾向が減りました。教える人が褒められたり、見過ごされたりする(つまりその行動によって罰せられない)と、子供たちは教える人の行動や、さらには言葉までをも真似しました。彼らは、人形を殴ったり、蹴ったり、それに向かって叫んだりしました。
学習へのリンク
有名なボボ人形の実験についてのビデオクリップ(http://openstax.org/l/bobodoll)で、実験の一部とアルバート・バンデューラのインタビューを見ることができます。
この研究はどのような意味を持っているのでしょうか?バンデューラは、人は見て学ぶものであり、この学習は、向社会的な効果と反社会的な効果の両方を持つことができると結論付けています。向社会的(肯定的)なモデルを用いて、社会的に許容可能な行動を促すことができます。特に親はこの発見に注意すべきです。もしあなたが子供に本を読ませたいのであれば、本を読んであげましょう。自分が読んでいる姿を子供に見せましょう。家に本を置いておきましょう。自分の好きな本について話してみましょう。もしあなたが子供たちに健康でいてほしいと望むなら、あなたが正しい食生活と運動をしている姿を見せ、一緒に身体の健康のための活動をする時間を持ちましょう。優しさや礼儀正しさ、誠実さなどの資質についても同じことが当てはまります。主となる考え方は、子供は親を観察し、親の道徳性すらも含めて親から学ぶということです。そのため、一貫性を保ち、「私がやっていることをやるのではなく、私が言ったことをやりなさい」という古い格言を捨てましょう。なぜなら、子供はあなたが言うことではなく、あなたがやっていることを真似する傾向があるからです。親以外にも、マーティン・ルーサー・キング・ジュニアやマハトマ・ガンジーなど、多くの公的な人物が、グローバルな社会変化を触発することのできる向社会的モデルと見なされています。あなたの人生において、向社会的モデルとなっている人に心当たりはありますか?
観察学習の反社会的な効果も言及するに値します。この節の冒頭のクレアの例で見たように、彼女の娘はクレアの攻撃的な行動を見て、それを真似しました。これは、被虐待児が成長するとしばしば自分自身も虐待者になることがある理由を説明するのに役立つかもしれない、ということが研究で示唆されています(Murrell, Christoff, & Henning, 2007)。実際、虐待を受けた子供の約30%が、虐待をする親になります(U.S. Department of Health & Human Services, 2013)。私たちは、自分が知っていることをする傾向があります。虐待を受けた子供たちは、親が怒りや不満を暴力的・攻撃的な行為で処理するのを目の当たりにして育ち、しばしば自分たちもそのような態様で行動するようになることを学びます。悲しいことに、この悪循環を断ち切るのは困難です。
いくつかの研究は暴力的なテレビ番組や映画、ビデオゲームも反社会的な影響を及ぼす可能性を示唆していますが(図6.18)、メディアの暴力と行動についての相関関係や因果関係の側面を理解するためには、さらなる研究が行われる必要があります。いくつかの研究は、暴力の視聴と子供に見られる攻撃性との間のつながりを発見しました(Anderson & Gentile, 2008; Kirsch, 2010; Miller, Grabell, Thomas, Bermann, & Graham-Bermann, 2012)。高校を卒業する子供は、それまでにさまざまな形態のメディアを通じて、殺人、強盗、拷問、爆弾、殴打、強姦を含む、約20万件の暴力的な行為にさらされていることを考えると(Huston et al., 1992)、こうした発見は驚くようなことではないかもしれません。メディアでの暴力の視聴は、現実の状況でそのように行動することを人々に教えることによって、攻撃的な行動に影響を与える可能性があるだけでなく、暴力的な行為に繰り返しさらされることで、人々がそれに鈍感になることも示唆されています。心理学者たちは、この動態を解明しようと取り組んでいます。

図6.18 | ビデオゲームは私たちを暴力的にするのでしょうか?心理学の研究者はこのトピックを研究しています。(credit: “woodleywonderworks”/Flickr)
学習へのリンク
暴力的なビデオゲームと暴力的な行動との間のつながりについてのビデオ(http://openstax.org/l/videogamevio)を見て、さらに学んでください。
あなたはどう考えますか?
暴力的なメディアと攻撃性
暴力的なメディアを見たり、暴力的なビデオゲームで遊んだりすると、攻撃性を引き起こすのでしょうか?アルバート・バンデューラの初期の研究は、テレビの暴力が子供の攻撃性を高めることを示唆しており、より最近の研究もこの知見を支持しています。たとえば、クレイグ・アンダーソンと同僚らの研究(Anderson, Bushman, Donnerstein, Hummer, & Warbuten, 2015; Anderson et al., 2010; Bushman et al., 2016)では、暴力的なメディアへの曝露時間と攻撃的な思考や行動との間に因果関係があることを示唆する広範な証拠が見つかっています。しかしながら、クリストファー・ファーガソンと他の人たちの研究では、暴力的なメディアへの曝露と攻撃性との間にはつながりがあるかもしれないが、これまでの研究では、メンタルヘルスや家庭生活を含む攻撃性についての他の危険因子を説明していないことが示唆されています(Ferguson, 2011; Gentile, 2016)。あなたはどう考えますか?
重要用語
獲得:古典的条件付けにおいて、人間や動物が中性刺激と無条件刺激を結びつけて、中性刺激が条件反応を引き起こすようになる初期学習の期間
連合学習:環境の中で一緒に起こる特定の刺激や出来事を結びつけることを伴う学習の形態(古典的条件付けとオペラント条件付け)
古典的条件付け:行動の前に刺激や経験が起こり、その刺激や経験が行動と対になったり関連付けられたりするような学習
認知地図:心の中での環境の配置の図
条件反応(CR):条件刺激によって引き起こされる反応
条件刺激(CS):無条件刺激と対になっていることで反応を引き起こす刺激
連続強化:行動が起こるたびに報酬を与えること
消去:無条件刺激がもはや条件刺激と対になっていないときに、条件反応が減少すること
固定間隔の強化スケジュール:既定の量の時間が経過した後に行動に対して報酬が与えられる
固定比率の強化スケジュール:行動に報酬が与えられる前に発生しなければならない反応の数が設定されている
高次の条件付け(または、二次の条件付け):条件刺激を用いて中性刺激を条件付けすること
本能:複雑な行動パターンを伴う学習されていない知識。本能は人間よりも下等な動物に多いと考えられている
潜在学習:学習は行われているものの、それを実証する理由がない限り、明らかにならないもの
効果の法則:生物にとって満足をもたらす帰結が続くような行動は繰り返され、不快な帰結が続くような行動は抑制される
学習:経験の結果として起こる行動や知識の変化
モデル:(観察学習において)手本となる行動をする人
負の弱化:行動を減少または停止させるために好ましい刺激を取り去ること
負の強化:行動を増加させるために望ましくない刺激を取り去ること
中性刺激(NS):当初は反応を引き起こさないような刺激
観察学習:他人を見ることによって生じる学習のタイプ
オペラント条件付け:行動が示された後に刺激/経験が起こる学習の形態
部分強化:時々だけ行動に報酬を与えること
正の弱化:行動を減少または停止させるために望ましくない刺激を加えること
正の強化:行動を増加させるために望ましい刺激を加えること
一次強化子:内在的に強化の性質を持つもの(例:食糧、水、住処、性交)
弱化:行動を減少させるために結果を与えること
急進的行動主義:B・F・スキナーによって開発された行動主義の頑固な形態で、人間の言語のような複雑な高次の精神機能でさえ、刺激と結果の関連性に過ぎないと示唆した
反射:環境中の刺激に対する、生物の学習されていない自動的な反応
強化:行動を増加させるために結果を与えること
二次強化子:それ自体には内在的な価値はなく、何か他のものと結びついたときにのみ強化の性質を発揮するもの(例:お金、成績優秀者の金色の星、ポーカーチップ)
シェーピング:標的とする行動に向かって漸次接近するものに報酬を与えること
自発的回復:以前に消去された条件反応が再び起こること
刺激分化:類似した刺激に対して異なる反応をする能力
刺激般化:条件刺激と類似した刺激に対して条件反応を示すこと
無条件反応(UCR):所与の刺激に対する自然な(学習されていない)行動
無条件刺激(UCS):反射的な反応を引き起こす刺激
可変間隔の強化スケジュール:予測できない時間が経過した後に行動に対して報酬が与えられる
可変比率の強化スケジュール:行動に報酬が与えられるまでの反応の数が異なる
代理弱化:モデルが罰せられているのを観察者が見て、モデルの行動を模倣しにくくなるようなプロセス
代理強化:モデルが報酬を与えられているのを観察者が見て、モデルの行動を模倣しやすくなるようなプロセス
この章のまとめ
6.1 学習とは何でしょうか?
本能と反射は生得的な行動で、自然に起こるものであり、学習を伴いません。これに対し、学習とは、経験によって生じる行動や知識の変化のことです。学習には大きく分けて、古典的条件付け、オペラント条件付け、観察学習の3種類があります。古典的条件付けもオペラント条件付けも、連合学習の一種です。連合学習とは、一緒に起こった事象を関連付けるものです。観察学習は、読んで字のごとく、他者を観察することにより学ぶものです。
6.2 古典的条件付け
パブロフによる犬を使った先駆的な研究は、私たちが学習について知っていることに対して大きく貢献しました。彼の実験は、現在では古典的条件付けと呼ばれているタイプの連合学習を探求したものです。古典的条件付けでは、生物は繰り返し一緒に起こる出来事を関連付けることを学習します。研究者は、ある刺激に対する反射的な反応が、別の刺激に対してどのように配列されるかを、2つの刺激の間の関連付けを訓練することによって研究します。パブロフの実験は、刺激と反応の結びつきがどのように形成されるかを示しています。行動主義の創始者であるワトソンは、パブロフの研究に多大な影響を受けました。彼は、アルバート坊やとして知られる乳児に恐怖を条件付けることにより人間を実験しました。彼の発見は、古典的条件付けが何らかの恐怖の生起を説明できることを示唆しています。
6.3 オペラント条件付け
オペラント条件付けは、B・F・スキナーの研究に基づいています。オペラント条件付けとは、行動に対する動機付けが、その行動が示された後に起こるような学習の一形態です。動物や人間は、特定の行動を行った後に結果を受け取ります。その結果は強化子か弱化子のどちらかです。すべての強化(正または負)は、行動反応の可能性を高めます。すべての弱化(正または負)は、行動反応の可能性を減少させます。強化スケジュールのいくつかのタイプは、設定された期間または可変期間のいずれかに応じて行動に報酬を与えるために使用されます。
6.4 観察学習(モデリング)
バンデューラによると、学習は他人を見て、その人の行動や発言をモデリングすることによって起こります。これは、観察学習として知られています。モデリングのプロセスには、学習を成功させるために従わなければならない特定の段階があります。これらの段階には、注意、保持、再生、および動機付けが含まれます。バンデューラは、モデリングを通して、子供は親や兄弟、他人を見るだけで、良いことも悪いことも含め多くのことを学ぶことを示しています。
レビュー問題
1.以下のうち、人間の発達のある時点で起こる反射の例はどれですか?
a.子供が自転車に乗る
b.10代の子が人と交流する
c.乳児が乳首を吸う
d.幼児が歩行する
2.学習とは、________、比較的永続的な行動の変化として、最もよく定義できます。
a.内在的な
b.経験の結果として起こる
c.人間にのみ見られる
d.他人を観察することによって起こる
3.連合学習の2つの形態は、(1)________と(2)________です。
a.(1)古典的条件付け、(2)オペラント条件付け
b.(1)古典的条件付け、(2)パブロフの条件付け
c.(1)オペラント条件付け、(2)観察学習
d.(1)オペラント条件付け、(2)学習条件付け
4.________では、行動の前に刺激や経験が起こり、その後でそれらが行動と対になります。
a.連合学習
b.観察学習
c.オペラント条件付け
d.古典的条件付け
5.最初は生物の反応を引き起こさないような刺激は、________です。
a.無条件刺激
b.中性刺激
c.条件刺激
d.無条件反応
6.ワトソンとレイナーの実験では、アルバート坊やは白いラットを恐れるように条件付けられ、その後、彼は他のフワフワした白い物体を恐れるようになりました。これは、________を示しています。
a.高次の条件付け
b.獲得
c.刺激分化
d.刺激般化
7.消去は、________ときに起こります。
a.条件刺激が無条件刺激とペアになることなく繰り返し提示される
b.無条件刺激が条件刺激とペアになることなく繰り返し提示される
c.中性刺激が無条件刺激とペアになることなく繰り返し提示される
d.中性刺激が条件刺激とペアになることなく繰り返し提示される
8.パブロフの犬を用いた研究では、精神的分泌は、________でした。
a.無条件反応
b.条件反応
c.無条件刺激
d.条件刺激
9.________とは、行動を止めるために、好ましい刺激を取り去ることです。
a.正の強化
b.負の強化
c.正の弱化
d.負の弱化
10.以下のうち、一次強化子の例ではないものはどれですか?
a.食べ物
b.お金
c.水
d.性交
11.標的とする行動に漸次接近するものに報酬を与えることは、________です。
a.シェーピング
b.消去
c.正の強化
d.負の強化
12.スロットマシンはどの強化スケジュールに従ってギャンブラーにお金を与えるでしょうか?
a.固定比率
b.可変比率
c.固定間隔
d.可変間隔
13.手本となる行動を行う人のことを、________といいます。
a.教師
b.モデル
c.指導者
d.コーチ
14.バンデューラのボボ人形の研究では、攻撃的なモデルを見た子供たちが、人形や他のおもちゃのある部屋に入れられると、彼らは________。
a.その人形を無視しました
b.その人形と仲良く遊びました
c.組み立ておもちゃで遊びました
d.人形を蹴ったり投げたりしました
15.モデリングのプロセスの段階の正しい順番はどれですか?
a.注意、保持、再生、動機付け
b.動機付け、注意、再生、保持
c.注意、動機付け、保持、再生
d.動機付け、注意、保持、再生
16.観察学習を提唱したのは誰ですか?
a.イワン・パブロフ
b.ジョン・ワトソン
c.アルバート・バンデューラ
d.B・F・スキナー
批判的思考の問題
17.古典的条件付けとオペラント条件付けを比較対照してください。それらはどのように似ていますか?どのように違いますか?
18.反射と学習された行動の違いは何ですか?
19.トースターがトーストを焼き上げる音で口の中によだれが出る場合、UCS、CS、およびCRは何ですか?
20.刺激般化と刺激分化のプロセスがどのように相反するものと考えられるかについて説明してください。
21.中性刺激はどのようにして条件刺激になるのでしょうか?
22.スキナー箱とは何ですか?また、その目的は何ですか?
23.負の強化と弱化との違いは何ですか?
24.シェーピングとは何ですか?そして、シェーピングを使ってどのようにして犬に寝返りを教えますか?
25.向社会的モデリングと反社会的モデリングの効果は何ですか?
26.カラは17歳です。カラの母親と父親は、毎晩お酒を飲んでいます。彼らはカラに、お酒を飲むのは悪いことだからやるべきではないと言っています。カラは、ビールが提供されているパーティーに行きます。カラは何をすると思いますか?その理由は何ですか?
個人的に当てはめてみる問題
27.あなたの個人的な学習の定義は何ですか?学習についてのあなたの考え方は、この教科書で提示された学習の定義とどのように比較できますか?
28.あなたは、古典的条件付けのプロセスを通じて、どのようなことを学びましたか?オペラント条件付けでは?観察学習では?あなたはそれらをどのようにして学びましたか?
29.古典的条件付けが、幸福や興奮などの肯定的な情動反応をもたらした例を、あなたの人生で思い浮かべることができますか?恐怖、不安、怒りなどの否定的な情動反応についてはどうでしょうか?
30.負の強化と弱化との違いを説明し、自分自身の経験に基づいてそれぞれの例をいくつか挙げてください。
31.あなたが変えたいと思っている行動を思い浮かべてください。あなたの行動を変えるために、行動変容、特に正の強化をどのように使うことができますか?あなたの正の強化子は何ですか?
32.あなたが誰かを見てやり方を学習したことは何ですか?
参考文献
Anderson, C. A., & Gentile, D. A. (2008). Media violence, aggression, and public policy. In E. Borgida & S. Fiske (Eds.), Beyond common sense: Psychological science in the courtroom (p. 322). Blackwell.
Anderson, C. A., Bushman, B. J., Donnerstein, E., Hummer, T. A., & Warburton, W. (2015). SPSSI research summary on media violence. Analyses of Social Issues and Public Policy (ASAP), 15(1), 4–19. https://doi.org/10.1111/asap.12093
Anderson, C. A., Shibuya, A., Ihori, N., Swing, E. L., Bushman, B. J., Sakamoto, A., Rothstein, H.R., & Saleem, M. (2010). Violent video game effects on aggression, empathy, and prosocial behavior in Eastern and Western countries: A meta-analytic review. Psychological Bulletin, 136(2), 151–173. HYPERLINK “https://psycnet.apa.org/doi/10.1037/a0018251”https://doi.org/10.1037/a0018251
Bandura, A., Ross, D., & Ross, S. A. (1961). Transmission of aggression through imitation of aggressive models. Journal of Abnormal and Social Psychology, 63, 575–582.
Bushman, B. J., Anderson, C. A., Donnerstein, E., Hummer, T. A., & Warburton, W. A. (2016). Reply to comments on SPSSI research summary on media violence by Cupit (2016), Gentile (2016), Glackin and Gray (2016), Gollwitzer (2016), and Krahé (2016). Analyses of Social Issues and Public Policy (ASAP), 16(1), 443–450. https://doi.org/10.1111/asap.12123
Cangi, K., & Daly, M. (2013). The effects of token economies on the occurrence of appropriate and inappropriate behaviors by children with autism in a social skills setting. West Chester University: Journal of Undergraduate Research. http://www.wcupa.edu/UndergraduateResearch/journal/documents/cangi_S2012.pdf
Carlson, L., Holscher, C., Shipley, T., & Conroy Dalton, R. (2010). Getting lost in buildings. Current Directions in Psychological Science, 19(5), 284–289.
Chance, P. (2009). Learning and behavior (6th ed.). Wadsworth, Cengage Learning.
Chase, H. W., & Clark, L. (2010). Gambling severity predicts midbrain response to near-miss outcomes. The Journal of Neuroscience, 30(18), 6180–6187. https://www.jneurosci.org/content/30/18/6180.short
Cialdini, R. B. (2008). Influence: Science and practice (5th ed.). Pearson Education.
DeAngelis, T. (2010). ‘Little Albert’ regains his identity. Monitor on Psychology, 41(1), 10.
Ferguson, C. J. (2011). Video games and youth violence: A prospective analysis in adolescents. Journal of Youth and Adolescence, 40(4), 377–391. https://link.springer.com/article/10.1007/s10964-010-9610-x
Fryer, R. G., Jr. (2010, April). Financial incentives and student achievement: Evidence from randomized trials. National Bureau of Economic Research [NBER] Working Paper, No. 15898. http://www.nber.org/papers/w15898
Garcia, J., & Koelling, R. A. (1966). Relation of cue to consequence in avoidance learning. Psychonomic Science, 4, 123–124.
Garcia, J., & Rusiniak, K. W. (1980). What the nose learns from the mouth. In D. Müller-Schwarze & R. M. Silverstein (Eds.), Chemical signals: Vertebrates and aquatic invertebrates (pp. 141–156). Plenum Press.
Gentile, D. A. (2016). The evolution of scientific skepticism in the media violence “debate.” Analyses of Social Issues and Public Policy, 16, 429–434.
Gershoff, E. T. (2002). Corporal punishment by parents and associated child behaviors and experiences: A meta-analytic and theoretical review. Psychological Bulletin, 128(4), 539–579. doi:10.1037//0033-2909.128.4.539
Gershoff, E.T., Grogan-Kaylor, A., Lansford, J. E., Chang, L., Zelli, A., Deater-Deckard, K., & Dodge, K. A. (2010). Parent discipline practices in an international sample: Associations with child behaviors and moderation by perceived normativeness. Child Development, 81(2), 487–502.
Hickock, G. (2010). The role of mirror neurons in speech and language processing. Brain and Language, 112, 1–2.
Holmes, S. (1993). Food avoidance in patients undergoing cancer chemotherapy. Support Care Cancer, 1(6), 326–330.
Hunt, M. (2007). The story of psychology. Doubleday.
Huston, A. C., Donnerstein, E., Fairchild, H., Feshbach, N. D., Katz, P. A., Murray, J. P., . . . Zuckerman, D. (1992). Big world, small screen: The role of television in American society. University of Nebraska Press.
Hutton, J. L., Baracos, V. E., & Wismer, W. V. (2007). Chemosensory dysfunction is a primary factor in the evolution of declining nutritional status and quality of life with patients with advanced cancer. Journal of Pain Symptom Management, 33(2), 156–165.
Jacobsen, P. B., Bovbjerg, D. H., Schwartz, M. D., Andrykowski, M. A., Futterman, A. D., Gilewski, T., . . . Redd, W. H. (1993). Formation of food aversions in cancer patients receiving repeated infusions of chemotherapy. Behaviour Research and Therapy, 31(8), 739–748.
Kirsch, SJ (2010). Media and youth: A developmental perspective. Wiley Blackwell.
Laskowski, C. S., Dorchak, D. L., Ward, K. M., Christensen, D. R., & Euston, D. R. (2019). Can slot-machine reward schedules induce gambling addiction in rats? Journal of Gambling Studies, 35(3), 887–914. https://www.ncbi.nlm.nih.gov/pubmed/31049772
Lefrançois, G. R. (2012). Theories of human learning: What the professors said (6th ed.). Wadsworth, Cengage Learning.
Miller, L. E., Grabell, A., Thomas, A., Bermann, E., & Graham-Bermann, S. A. (2012). The associations between community violence, television violence, intimate partner violence, parent-child aggression, and aggression in sibling relationships of a sample of preschoolers. Psychology of Violence, 2(2), 165–78. doi:10.1037/a0027254
Murch, W. S., & Clark, L. (2016). Games in the brain: Neural substrates of gambling addiction. The Neuroscientist, 22(5), 534–545. https://www.ncbi.nlm.nih.gov/pubmed/26116634
Murrell, A., Christoff, K. & Henning, K. (2007) Characteristics of domestic violence offenders: associations with childhood exposure to violence. Journal of Family Violence, 22(7), 523-532.
Pavlov, I. P. (1927). Conditioned reflexes: An investigation of the physiological activity of the cerebral cortex (G. V. Anrep, Ed. & Trans.). Oxford University Press.
Potenza, M. N. (2013). Neurobiology of gambling behaviors. Current Opinion in Neurobiology, 23(4), 660–667. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3803105/
Rescorla, R. A., & Wagner, A. R. (1972). A theory of Pavlovian conditioning: Variations in the effectiveness of reinforcement and nonreinforcement. Classical Conditioning II: Current Research and Theory, 2, 64-99.
Rizzolatti, G., Fadiga, L., Fogassi, L., & Gallese, V. (2002). From mirror neurons to imitation: Facts and speculations. In A. N. Meltzoff & W. Prinz (Eds.), The imitative mind: Development, evolution, and brain bases (pp. 247–66). Cambridge University Press.
Rizzolatti, G., Fogassi, L., & Gallese, V. (2006, November). Mirrors in the mind. Scientific American, pp. 54–61.
Skinner, B. F. (1938). The behavior of organisms: An experimental analysis. Appleton-Century-Crofts.
Skinner, B. F. (1953). Science and human behavior. Macmillan.
Skinner, B. F. (1961). Cumulative record: A selection of papers. Appleton-Century-Crofts.
Skinner’s utopia: Panacea, or path to hell? (1971, September 20). Time. http://www.wou.edu/~girodm/611/Skinner%27s_utopia.pdf
Skolin, I., Wahlin, Y. B., Broman, D. A., Hursti, U-K. K., Larsson, M. V., & Hernell, O. (2006). Altered food intake and taste perception in children with cancer after start of chemotherapy: Perspectives of children, parents and nurses. Supportive Care in Cancer, 14, 369–78.
Thorndike, E. L. (1911). Animal intelligence: An experimental study of the associative processes in animals. Psychological Monographs, 8.
Tolman, E. C., & Honzik, C. H. (1930). Degrees of hunger, reward, and non-reward, and maze performance in rats. University of California Publications in Psychology, 4, 241–256.
Tolman, E. C., Ritchie, B. F., & Kalish, D. (1946). Studies in spatial learning: II. Place learning versus response learning. Journal of Experimental Psychology, 36, 221–229. doi:10.1037/h0060262
Watson, J. B. & Rayner, R. (1920). Conditioned emotional reactions. Journal of Experimental Psychology, 3, 1–14.
Watson, J. B. (1919). Psychology from the standpoint of a behaviorist. J. B. Lippincott.
Yamamoto, S., Humle, T., & Tanaka, M. (2013). Basis for cumulative cultural evolution in chimpanzees: Social learning of a more efficient tool-use technique. PLoS ONE, 8(1): e55768. doi:10.1371/journal.pone.0055768
この訳文は元の本のCreative Commons BY 4.0ライセンスに従って同ライセンスにて公開します。問題がありましたら、可能な限り早く対応いたしますので、ご連絡ください。また、誤訳・不適切な表現等ありましたらご指摘ください。この本は、https://openstax.org/details/books/psychology-2eで無料でダウンロードできます。